DeepSeek-R1 本地化部署
DeepSeek-R1 是 深度求索 推出的高性能模型,尤其擅长数学逻辑与代码生成,性能对标 OpenAI o1 正式版。本地部署推荐选择其蒸馏版量化模型(如1.5B/7B/32B),通过Ollama适配后,显存需求显著降低(8GB显存可运行8B模型)。
[TOC]
本地化部署步骤
1.安装 Ollama
- Ollama 是一个开源的本地化大模型部署工具,旨在简化大型语言模型(LLM)的安装、运行和管理。它支持多种模型架构,并提供与 OpenAI 兼容的 API 接口,适合开发者和企业快速搭建私有化 AI 服务。
- Windows用户:访问 https://ollama.com/download 下载安装包(若官网下载失败,点我下载),双击运行并完成初始化
#.配置永久系统变量, 将默认监听从 127.0.0.1:11434 调整为 0.0.0.0:11434
setx OLLAMA_HOST 0.0.0.0:11434 /m
#.安装ollama到指定目录
cd /d d:\
wget -c http://iso.sqlfans.cn/ai/ollama/0.5.7/OllamaSetup.exe
OllamaSetup.exe /DIR="D:\tools\ollama"
#.确认端口已监听
netstat -ano | findstr 11434
- Linux用户:通过如下命令行一键安装
#.安装ollama
curl -fsSL https://ollama.com/install.sh | sh
systemctl start ollama
ollama --version
#.调整ollama服务, 将默认监听从 127.0.0.1:11434 调整为 0.0.0.0:11434
cat /etc/systemd/system/ollama.service | grep OLLAMA_HOST || sed -i '/Environment/a\Environment="OLLAMA_HOST=0.0.0.0:11434"' /etc/systemd/system/ollama.service
cat /etc/systemd/system/ollama.service | grep -A 8 "\[Service\]"
#.重启ollama服务
systemctl daemon-reload
systemctl restart ollama
#.确认端口已监听
netstat -lnpt | grep 11434
- 成功安装之后,浏览器访问 Ollama 地址:
http://127.0.0.1:11434
2.拉取 DeepSeek 模型
- 访问 https://ollama.com/search 找到 deepseek-r1,关于不同模型的对比可参考下表(B代表Billion,7B即70亿参数):
| ds模型 | 参数量 | 模型大小 | 建议配置 | 备注 |
|---|---|---|---|---|
| deepseek-r1:1.5b | 1.5B | 1.1GB | 4核、8GB、集成显卡(无需独立显存) | 超轻量模型 |
| deepseek-r1:7b | 7B | 4.7GB | 6核、16GB、RTX 3060级(共6GB显存) | 默认版本,性能与OpenAl-01相当 |
| deepseek-r1:8b | 8B | 4.9GB | 8核、24GB、RTX 3070/4060(共8GB显存) | 硬件与性能比 7B 略高 10-20% |
| deepseek-r1:14b | 14B | 9GB | 12核、64GB、2块RTX 4000Ada(共40GB显存) | 中等规模,企业级 |
| deepseek-r1:32b | 32B | 20GB | 24核、128GB、4块RTX 4000Ada(共80GB显存) | 高性能 |
| deepseek-r1:70b | 70B | 43GB | 32核、256GB、4块RTX 5880Ada(共192GB显存) | 超高性能 |
| deepseek-r1:671b | 671B | 404GB | 64核、1TB、8块A100(共640GB显存) | 满血版,性能对标OpenAI-o1正式版 |
- 根据硬件选择合适的模型版本,示例拉取 deepseek-r1:1.5b 模型,大小约 1.1 GB、速度约 489 KB/s
#.若下载速度越来越慢,可按 Ctrl+C 取消并重新下载(支持断点续传,亲测有效)
ollama pull deepseek-r1:1.5b
ollama list
注:模型越大效果越好,但需权衡计算资源。7B模型则在性能和资源需求之间达到了一个较好的平衡,它具备更强的语言理解和生成能力,能够处理更复杂的任务,如内容创作、智能客服等。
3.启动 DeepSeek 模型交互
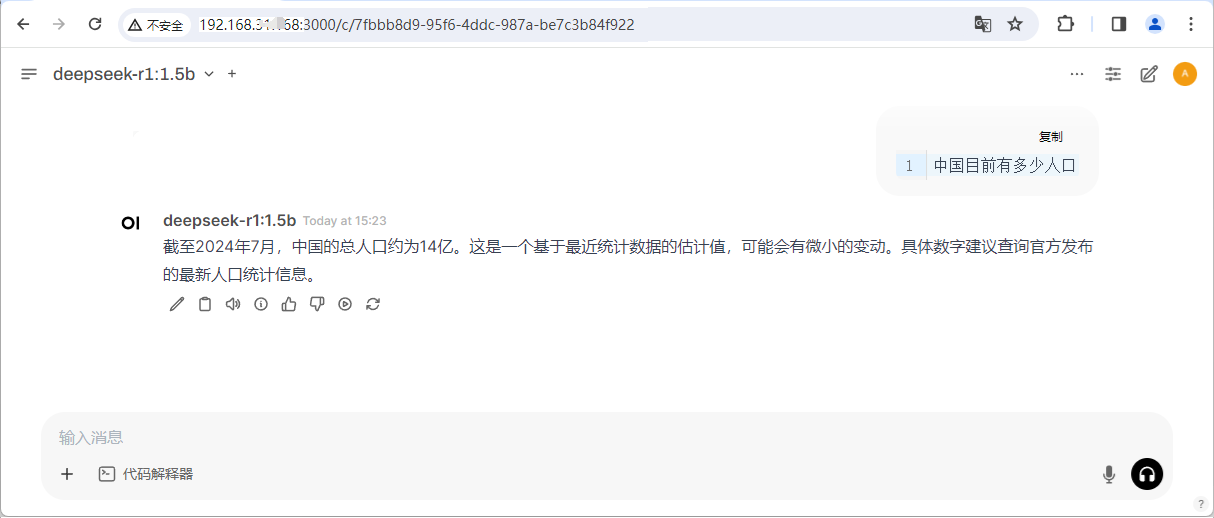
- 启动 DeepSeek 模型交互,示例启动 deepseek-r1:1.5b 模型
ollama run deepseek-r1:1.5b
- 启动后进入REPL界面,输入问题即可获得回答,输入
/bye退出会话
>>> 中国目前有多少人口
>>> /bye
4.安装 Open WebUI 可视化界面 [选做]
- 安装 docker 24.0.1
curl -sL 'http://iso.sqlfans.cn/docker/install_docker_2401.sh' | bash
docker --version
- 启动 DeepSeek 模型交互(若退出模型交互则无法获取模型),以供容器服务使用
ollama run deepseek-r1:1.5b &
- 以 docker 方式部署 Open WebUI,容器初始化约3分钟
#.windows部署方式1 - 使用 --add-host 允许docker容器访问宿主机服务
mkdir d:\tools\webui
docker pull ghcr.io/open-webui/open-webui:main
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v d:\tools\webui:/app/backend/data --name open_webui ghcr.io/open-webui/open-webui:main
#.windows部署方式2 - 使用 -e OLLAMA_BASE_URL 显式指定 ollama 地址
mkdir d:\tools\webui
docker pull ghcr.io/open-webui/open-webui:main
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=http://192.168.31.168:11434 -v d:\tools\webui:/app/backend/data --name open_webui ghcr.io/open-webui/open-webui:main
#.linux系统, 不支持 --add-host, 只能使用 -e OLLAMA_BASE_URL 显式指定 ollama 地址
mkdir -p /data/webui
docker pull ghcr.io/open-webui/open-webui:main
docker run --privileged=true -d -p 3000:8080 -e OLLAMA_BASE_URL=http://192.168.31.101:11434 -v /data/webui:/app/backend/data --name open_webui ghcr.io/open-webui/open-webui:main
- 登录 webui控制台
http://localhost:3000,配置管理员账号及密码,待初始化完成之后就可以进行对话了
注:正常情况下,不需要在“设置 - 管理员设置 - 外部连接 与 模型”中绑定 Ollama地址 与 DeepSeek模型
进阶优化与安全
性能调优技巧
- GPU加速:Windows设置环境变量
$env:OLLAMA_GPU="enable",Linux添加OLLAMA_GPU_LAYERS=35 - 量化压缩:通过
ollama create <模型名称> -f modelfile自定义配置量化参数(如 q4_k_m),减少显存占用
安全加固
- https加密:使用OpenSSL生成证书并配置反向代理
- 权限管理:通过JWT令牌验证API请求,限制访问IP
- 数据隔离:将模型与用户数据分离存储,避免敏感信息泄露
遇到的问题
问题1:ollama pull 下载模型超时
- 症状:由于网络不稳定,导致下载模型超时
- 解决:使用国内镜像源并重新拉取,或者按 Ctrl+C 取消并重新拉取(支持断点续传,亲测有效)
问题2:ollama run 报错内存不足
- 症状:在一台2核2G的机器上执行 ollama run 报错内存不足
- 解决:增加内存或更换机器
[root@localhost ~]# ollama run deepseek-r1:1.5b
Error: model requires more system memory (1.7 GiB) than is available (658.0 MiB)
[root@localhost ~]# free -m
total used free shared buff/cache available
Mem: 1837 921 378 96 537 665
Swap: 0 0 0
问题3:open-webui 容器启动失败
- 症状:启动 open webui 容器之后,端口虽已监听但telnet失败,docker ps 看到该容器状态为 unhealthy,执行 docker logs -f 看到报错 Failed to send telemetry event ClientStartEvent: can't start new thread
- 解决:执行 docker logs 看到该容器报权限问题,解决办法是在 docker run 之后紧跟添加 --privileged=true(顺序有要求) 对容器中的root用户进行提权,使其拥有对宿主机的root操作权限
[root@localhost ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
0c6512c3b49b ghcr.io/open-webui/open-webui:main "bash start.sh" 4 minutes ago Up 2 minutes (unhealthy) 0.0.0.0:3000->8080/tcp open_webui
[root@localhost ~]# docker logs -f 0c6512c3b49b
ERROR [chromadb.telemetry.product.posthog] Failed to send telemetry event ClientStartEvent: can't start new thread
OpenBLAS blas_thread_init: pthread_create failed for thread 1 of 8: Operation not permitted
OpenBLAS blas_thread_init: RLIMIT_NPROC -1 current, -1 max
OpenBLAS blas_thread_init: ensure that your address space and process count limits are big enough (ulimit -a)
OpenBLAS blas_thread_init: or set a smaller OPENBLAS_NUM_THREADS to fit into what you have available
[root@localhost ~]# ulimit -n
65535
问题4:open-webui 无法获取模型
- 症状:登录open webui管理员面板,点击 模型 - 管理模型 提示 无法获取模型 且右上角报错 Open WebUI: Server Connection Error
- 解决:首先执行 ollama run 启动模型交互(不可退出),然后启动 open-webui 容器添加参数
--add-host=host.docker.internal:host-gateway允许docker容器访问宿主机服务,或者显式指定-e OLLAMA_BASE_URL=http://192.168.31.168:11434(前提是监听了 0.0.0.0:11434 而非 127.0.0.1:11434)
问题5:open-webui 页面白屏
- 症状1:执行 docker run 启动 Open WebUI 容器之后,3000端口虽已监听,但telnet不通
- 解决1:初始化速度比较慢,多等一会吧,预计3分钟+
补充:
http://localhost:3000第一次打开是白屏也是因为初始化未完成,再等一等吧
- 症状2:open-webui 提供web界面,如果机器没有科学上网的话,登录后会长时间的空白,需要等待很久才会出现内容的情况
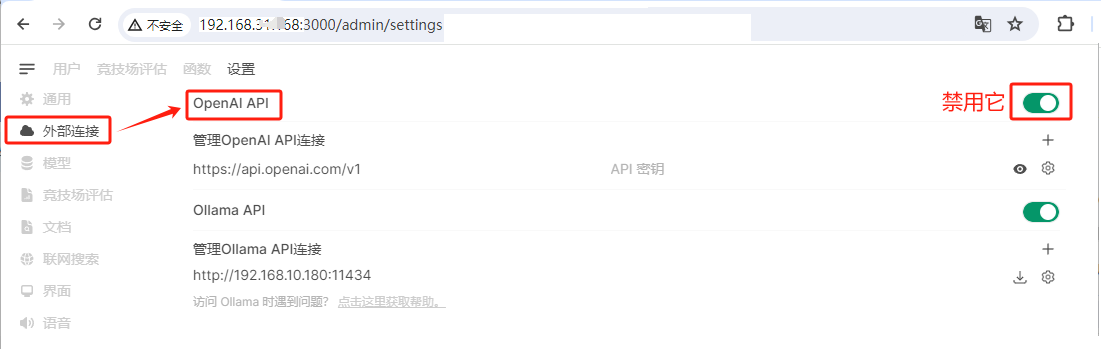
- 原因2:这个其实是因为默认对接了open-ai的Api,但是没有科学上网的话,会一直等待响应,只需要关闭即可
- 解决2:登录
http://localhost:3000/admin/settings打开 管理员面板 - 外部连接,禁用 OpenAI API