新型数据库
[TOC]
概述
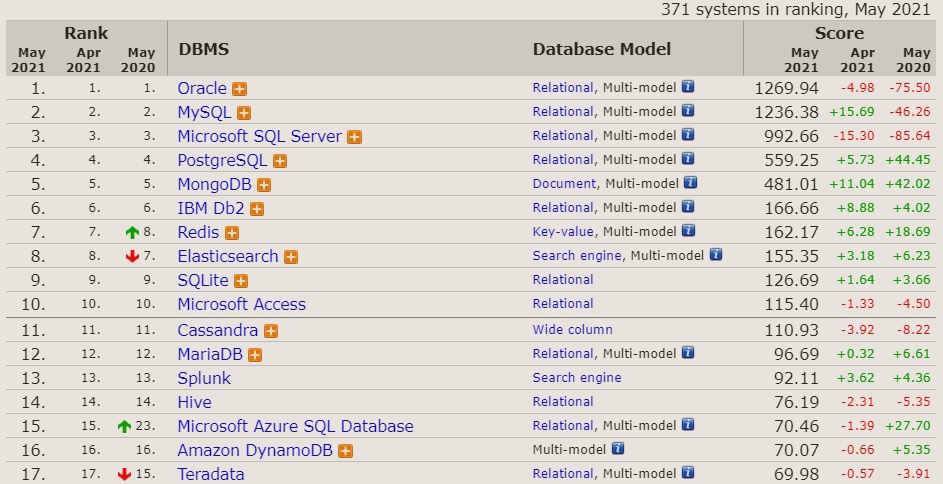
全球数据库排名:DB-Engines Ranking
主流 NewSQL 数据库
PostgreSQL
1.优点
- PostgreSQL遵循的是BSD协议,完全开源免费且不会被任何商业公司控制;而MySQL被Oracle收购之后慢慢走向封闭。
- PostgreSQL源代码堪称C语言的规范,易读性比MySQL强很多。
- 可靠性是PostgreSQL的最高优先级。它完全支持ACID特性,对于数据库访问提供了强大的安全性保证。
- PostgreSQL是多进程的,而MySQL是多线程的。虽然并发不高时,MySQL处理速度快;但是当并发高时,对于现在的多核的单台机器上,MySQL的总体性能不如PostgreSQL,原因是MySQL的线程无法充分利用CPU的能力。
- PostgreSQL有很强大的查询优化器,支持很复杂的查询处理,而MySQL对复杂查询处理较弱,查询优化器不够成熟。
2.缺点
3.典型的应用场景
4.不适合的场景
Tidb (企业版收费)
1.优点
- 活跃的开源社区,数据库领域顶尖的开源技术
- 兼容MySQL协议,几乎无需修改代码,提供数据迁移工具,迁移成本极低
- 分布式事务,把TiDB看做是一个单机RDBMS。跨多个机器启动事务,不影响一致性
- 故障自动恢复,无需人工干预,真正意义的Auto-Failover
- 在线DDL,按需更新TiDB Schema,添加新的列和索引,不影响当前业务
- 弹性扩展,加机器等于加性能
2.缺点
- 有热点写入问题,导致不使用分表方案的话,插入性能被限制为单台服务器性能,而不是线性扩容
- 相比mysql,性能差很多,读写延时很高,必须ssd
- 人力学习成本
3.典型的应用场景
- 原业务的 MySQL 的业务遇到单机容量或者性能瓶颈时
- 大数据量下,MySQL 复杂查询很慢
- 大数据量下,数据增长很快,接近单机处理的极限,不想分库分表或者使用数据库中间件等对业务侵入性较大、对业务有约束的 Sharding 方案
- 大数据量下,有高并发实时写入、实时查询、实时统计分析的需求
- 有分布式事务、多数据中心的数据 100% 强一致性、auto-failover 的高可用的需求
4.不适合的场景
- 单机 MySQL 能满足的场景也用不到 TiDB
- 数据条数少于 5000w 的场景下通常用不到 TiDB,TiDB 是为大规模的数据场景设计的
- 如果你的应用数据量小(所有数据千万级别行以下),且没有高可用、强一致性或者多数据中心复制等要求,那么就不适合使用 TiDB。
主流 NoSQL 数据库
概述
NoSQL(Not only SQL)泛指非关系型数据库,是一项全新的数据库革命性运动,NoSQL的拥护者们提倡运用非关系型的数据存储。现今的计算机体系结构在数据存储方面要求具备庞大的水平扩展性,而NoSQL致力于改变这一现状。目前Google的BigTable和Amazon的Dynamo使用的就是NoSQL型数据库。
但是NoSQL数据库之间的不同,远超关系型数据库之间的差别。这意味着DBA架构师更应该在项目开始时就选择好一个适合的 NoSQL 数据库。
针对这种情况,这里对 Cassandra、Mongodb、CouchDB、Redis、Riak、Membase、Neo4j、HBase 进行了比较:
NoSQL没有约定俗成的定义,常见观点如下:
- 不使用关系模型
- 在集群上运行良好
- 主要是开源的
- 适合构建21世纪Web应用
- 非模式化
NoSQL与关系数据库的区别
- NoSQL绝对不支持Join
NoSQL其实否定了关系数据库的第二索引和join。joins导致数据库切分sharding无法实施。见CAP定理。
NoSQL分类
- 1、Key-value stores面向键值,保存keys+BLOBs(二进制大对象Binary Large OBjects),如 Memcached和Redis
- 2、Table-oriented 面向表列,如 Google的BigTable和Cassandra
- 3、Document-oriented面向文档,文本是一种类似XML文档,如 MongoDB 和 CouchDB
- 4、Graph-oriented 面向图论,如 Neo4J
面向文档与面向表列或键值存储的区别
- 面向表列或键值存储,需要定义数据结构(半结构化)
- 面向文档无需结构(非结构化)
HBase
优势
- 1、存储容量大,一个表可以容纳上亿行 x 上百万列;
- 2、可通过版本进行检索,能搜到所需的历史版本数据;
- 3、负载高时,可通过简单的添加机器来实现水平切分扩展,跟Hadoop的无缝集成保障了其数据可靠性(HDFS)和海量数据分析的高性能(MapReduce);
- 4、在第3点的基础上可有效避免单点故障的发生。
缺点
- 1、基于Java语言实现及Hadoop架构意味着其API更适用于Java项目;
- 2、node开发环境下所需依赖项较多、配置麻烦(或不知如何配置,如持久化配置),缺乏文档;
- 3、占用内存很大,且鉴于建立在为批量分析而优化的HDFS上,导致读取性能不高;
- 4、API相比其它 NoSql 的相对笨拙。
适用场景
- 1、bigtable类型的数据存储
- 2、对数据有版本查询需求
- 3、应对超大数据量要求扩展简单的需求
- 4、随机实时的读写操作,高吞吐量写,随机访问大数据集
案例
- Facebook 消息数据库
Redis - 键值数据库
关键点
- 只有Redis有事务机制
- 通过定时snapshot快照和基于语句的aof追加,redis支持数据持久化
优势
- 1、非常丰富的数据结构;
- 2、Redis提供了事务的功能,可以保证一串命令的原子性,中间不会被任何操作打断;
- 3、数据存在内存中,读写非常的高速,可以达到10w/s的频率。
测试数据可参考《Redis千万级的数据量的性能测试》
缺点
- 1、Redis 3.0后才出来官方的集群方案,但仍存在一些架构上的问题;
- 2、持久化功能体验不佳——通过快照方法实现的话,需要每隔一段时间将整个数据库的数据写到磁盘上,代价非常高;而aof方法只追踪变化的数据,类似于mysql的binlog方法,但追加log可能过大,同时所有操作均要重新执行一遍,恢复速度慢;
- 3、由于是内存数据库,所以单台机器存储的数据量,跟机器本身的内存大小。虽然redis本身有key过期策略,但是还是需要提前预估和节约内存。如果内存增长过快,需要定期删除数据。
3.适用场景
适用于数据变化快且数据库大小可预见(适合内存容量)的应用程序。
- 在主页中显示最新的项目列表。因为Redis使用的是常驻内存的缓存,速度非常快。
- 删除和过滤。
- 排行榜及相关问题。
- 按照用户投票和时间排序。
MongoDB - 文档数据库
优势
- 1、强大的自动化 shading 功能;
- 2、全索引支持,查询非常高效;
- 3、面向文档(BSON)存储,数据模式简单而强大。
- 4、支持动态查询,查询指令也使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
- 5、支持 javascript 表达式查询,可在服务器端执行任意的 javascript函数。
缺点
- 1、单个文档大小限制为16M,32位系统上,不支持大于2.5G的数据;
- 2、对内存要求比较大,至少要保证热数据(索引,数据及系统其它开销)都能装进内存,即数据集大于内存很慢;
- 3、非事务机制,无法保证事件的原子性。
适用场景
- 1、适用于实时的插入、更新与查询的需求,并具备应用程序实时数据存储所需的复制及高度伸缩性;
- 2、非常适合文档化格式的存储及查询;
- 3、高伸缩性的场景:MongoDB 非常适合由数十或者数百台服务器组成的数据库。
- 4、对性能的关注超过对功能的要求。
案例
- 适合90%所有MySQL等RDBM场合
Couchbase
本文之所以没有介绍 CouchDB 或 Membase,是因为它们合并了。合并之后的公司基于 Membase 与 CouchDB 开发了一款新产品,新产品的名字叫做 Couchbase。
Couchbase 可以说是集合众家之长,目前应该是最先进的Cache系统,其开发语言是 C/C++。
Couchbase Server 是个面向文档的数据库(其所用的技术来自于Apache CouchDB项目),能够实现水平伸缩,并且对于数据的读写来说都能提供低延迟的访问(这要归功于Membase技术)。
关键点
- 写操作不会阻塞读操作
优势
- 1、高并发性,高灵活性,高拓展性,容错性好;
- 2、以 vBucket 的概念实现更理想化的自动分片以及动态扩容;
缺点
- 1、Couchbase 的存储方式为 Key/Value,但 Value 的类型很为单一,不支持数组。另外也不会自动创建doc id,需要为每一文档指定一个用于存储的 Document Indentifer;
- 2、各种组件拼接而成,都是c++实现,导致复杂度过高,遇到奇怪的性能问题排查比较困难,(中文)文档比较欠缺;
- 3、采用缓存全部key的策略,需要大量内存。节点宕机时 failover 过程有不可用时间,并且有部分数据丢失的可能,在高负载系统上有假死现象;
- 4、逐渐倾向于闭源,社区版本(免费,但不提供官方维护升级)和商业版本之间差距比较大。
适用场景
- 1、适合对读写速度要求较高,但服务器负荷和内存花销可遇见的需求;
- 2、需要支持 memcached 协议的需求。
NEO4J
- 图数据库,适合社会网络应用 LinkedIn Facebook 文件系统 角色关系
- 由nodes, relationships and properties.组成
- 内存中的节点图,自动持久