mha切换丢失数据
[TOC]
1、事故分析
时间轴
| 时间点 | 10.1.8.30 | 10.1.8.31 | 操作 | 描述 |
|---|---|---|---|---|
| 07-04 20:20 | 主库 | 备库 | 添加字段 | 数据库异常,触发内部重启,自动重启 |
| 07-04 20:26 | 备库 | 主库 | 高可用探测主库异常,自动切换 非候选从库(10.1.8.32) apply主库的差异数据失败 |
|
| 07-04 20:30 | 备库 | 主库 | 备库上添加尝试 | 问题重现,一段时候后自动重启了 |
| 07-06 xx:xx | 备库 | 主库 | 备库数据库版本升级,并且重新搭建了主备链条 | 从官方版本升级到percona分支,恢复是从当时非候选从库(10.1.8.32)上拿的备份 |
| 07-11 21:00 | 主库 | 备库 | 主备切换 | 切换动作没有异常 |
| 07-12 13:30 | 主库 | 备份 | 发现数据不对 |
丢数据原因
- 7月4号晚添加字段导致主库(10.1.8.30)异常,触发高可用自动切换;非候选从库(10.1.8.32)apply主库的差异数据失败;后续升级分支版本重建10.1.8.30备库时,从10.1.8.32上面拿的备份,最终做数据库切换时,由于30的数据是从32上恢复来的,导致数据丢失。
- 正常情况下导致丢数据的错误是会引起链条同步状态异常,而且会有对应报警的,但是上周的数据同步错误输出到日志[warning],且链条状态正常没有报警,引起DBA误判。
时间线详细描述
1.主库添加字段,表数据量一共500万行左右,按规范我们在20:00之后操作,7月4号的20:20分进行加字段操作,正常情况500万行很快加完,但执行了大概300秒左右(还没执行完,觉得异常),并进行了kill操作,但kill了会话还一直在运行

在添加字段的时,业务都是正常连接数据的,操作大概100s后日志一直报有锁的信息,如下图示:

从源码分析所等待的函数为:buf_flush_page,要刷新脏数据被fut0fut所阻塞,阻塞者是在获取buf_page,但迟迟没有获取到,一直持有锁
2.此时服务器的压力很小,cpu使用5%不到,io更是没有压力
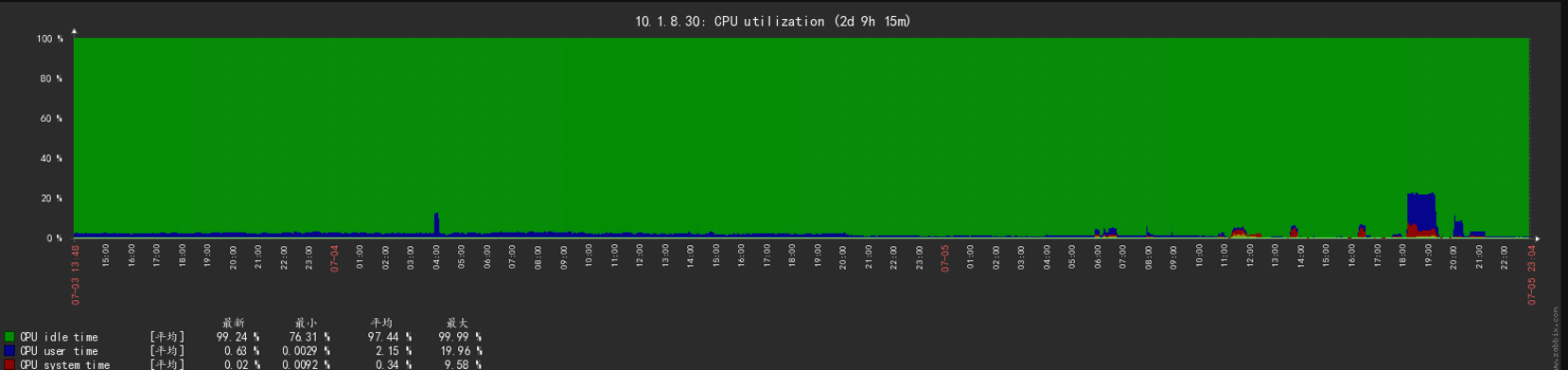
在这样的情况之后大概10分钟之后,数据自己自动重启纠错,由于有高可用机制,自动切换到了备库

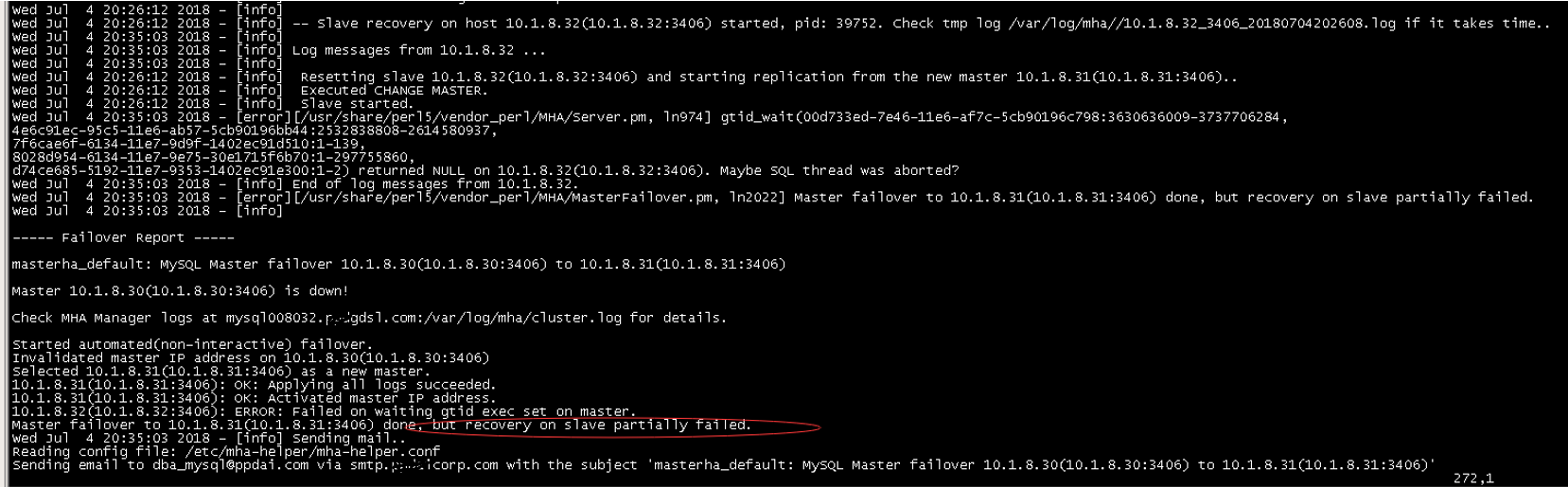
但是在切换的时候,其他备库recovery失败了,导致了后面的问题
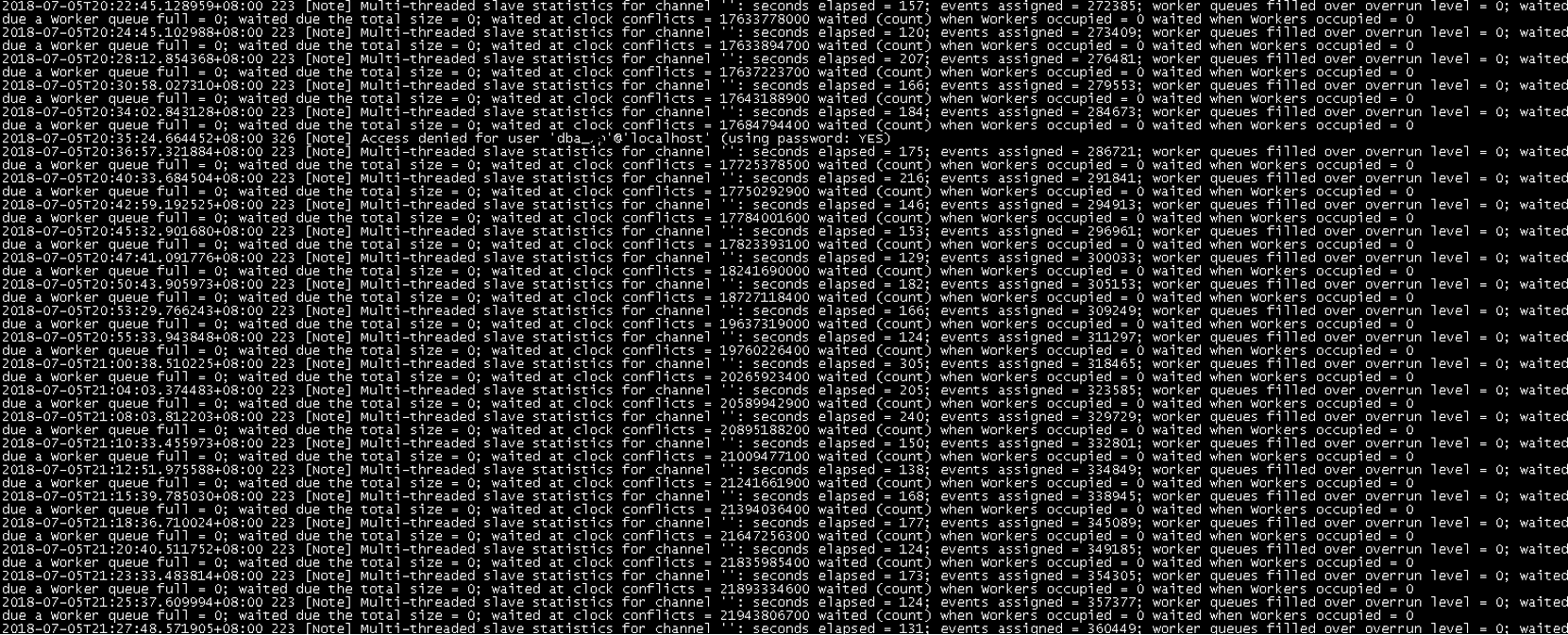
后续我们check了切换后的主从关系(同步进程和数据库日志),数据同步都显示正常,没有报错,下面是同步的日志
在处理好切换后的相关工作后,在备库上(切换后的备库),没有任何连接的情况下,我们执行试下了(看能否重现),情况和上面的一样,执行一段时间后,kill也kill不掉

结合上述的现象和已知官方版本 global InnoDB buffer pool 是一个单一的mutex,只要涉及到buff操作都会争用,所以考虑升级数据库分支。
另外一个分支percona版本(这个分支做了大量的性能优化,粒度化了各种全局锁,线上大部分都已经跑的这个版本)

3.在此之后我们升级了备库的数据库版本,并且重建搭建了同步链条
4.在7月11号晚上9点做数据库切换操作,并且切换顺利
5.7月12号下午,开发同事说有客户发现订阅的数据不对(7月6号的),让DBA排查下,发现确实有部分数据同步有问题
2、数据丢失和修补情况
- 市场策略丢失3万多条,已经修补完成
- Crm丢失133条,已经修补完成
以上修补结果,开发同事已经通过job对比数据,显示正常
3、发现的问题
- 数据库高可用自动切换后,只凭数据库自身的同步状态和日志来判断有可能存在漏洞
- 数据同步异常错误输出至错误日志的标记是有可能是[warning]而非[error],且在这种情况下主从同步状态“显示为正常”(实际已不同步),导致对数据库同步状态的判断有误
4、后续整改
- 1、规范数据库在线切换细则
- 2、数据库高可用自动切换后,对新的高可用架构做数据一致性校验
- 3、添加对错误日志[warning]标签中的error告警
- 4、调研强一致性的数据库高可用架构(如:PXC、MGR等),并寻找非关键业务尝试
5、mha主备切换操作规范
数据库主备切换操作规范,适用于mha在线切换,主从切换,迁移等。
a) 操作步骤
- 操作步骤按照表格的形式列出(见最后)
- 步骤确认后,抄送dba组
b) 操作前
- 数据一致性检查(数据量较大,提前准备)
- 错误日志(确保无error和相关同步的waring)
- 检查binglog server
- 检查近期备份
- 检查mha配置
- 检查主从配置差异
c) 操作
- 检查切换日志
- 检查数据库日志
- 检查数据库切换后的同步状态
d) 操作后
- 监控调整
- 备份调整
- 元数据调整(db_portal/dbconfig)
- Binlog server地址的变更
- etl地址变更通知到大数据等
- event状态的check(如有,确保从库不能为enable)
- 归档调整
- 从库域名刷新
- mha管理进程的启动
6、mha切换详细操作步骤
| 序号 | 步骤 | 状态 | 操作人 | 说明 |
|---|---|---|---|---|
| 1 | 主从数据库一致性检查 | 主从数据一致 | 日志 /tmp/dba_xxx/pt-check-sum.log | |
| 2 | 主从错误日志的check | 无error,waring | 日志 /tmp/dba_xxx/pre.log(需要cp存档) | |
| 3 | binlog server | 正常启动,并备份 | ||
| 4 | 数据库备份 | 近期有备份,无错误 | ||
| 5 | mha配置检查 Manger进程正常 Manger进程的日志 masterha_check_repl masterha_check_ssh masterha_check_status |
日志无错误,各状态正常 | 日志 /tmp/dba_xxx/下 | |
| 6 | 主从配置文件检查 | 无需调整,2边关键参数一样 | 配置文件在 /tmp/dba_xxx/ 下 | |
| 7 | 在线切换 | 正常 | 切换日志在/tmp/dba_xxx/下 | |
| 8 | 切换后的数据库日志检查 | 无报错 | 日志 /tmp/dba_xxx/post.log(需要cp存档) | |
| 9 | 切换后数据库同步状态 | 正常同步 | ||
| 10 | 监控调整 | 已调整 | ||
| 11 | 备份调整 | 已调整 | ||
| 12 | 元数据调整 | 已调整 | ||
| 13 | binlog server地址调整 | 已调整 | ||
| 14 | etl地址变更通知 | 已通知 | 已告知etl团队 | |
| 15 | event主从库状态的变更 | 已调整 | ||
| 16 | 从库域名解析变更 | 已调整 | xxx-slave01 的地址变更为 xxx | |
| 17 | 归档调整 | 已调整 | ||
| 18 | 调整mha配置为新的架构,并启动mang进程 | 已调整 | 启动正常 |