redis引发OOM Killer
记录一起因为压力测试导致Redis不断占用大量内存(直到触发RDB持久化)而被Out Of Memory机制杀死的问题。
[TOC]
故障上报
- 2021-09-29 测试同事反馈一台 Reids(192.168.200.101,内存8GB)于 2021-09-28 04:19 发生服务停止,后于 20:23 手动启动
分析过程
- 第1步,查看redis停止前后的错误日志(redis停止之前截图了3次RDB持久化日志),可以得到如下信息:
1、每次RDB持久化间隔5分钟,可以佐证持久化配置必然有 save 300 100(配置确实有),即每300秒有100次变更就做一次持久化;
[root@192.168.200.101]# cat /opt/redis/node1_redis.conf | grep save
save 3600 1
save 300 100
save 60 10000
2、第3次持久化使用的内存从15MB突增到4462MB(RDB: 4462 MB of memory used by copy-on-write),说明最近5分钟变更的数据超过了4462MB,但这5分钟网卡接收流量仅为450MB(平均带宽12Mbps x 300s / 8bit),所以得出最近5分钟变更的数据必然有bigkey(开发确认有);
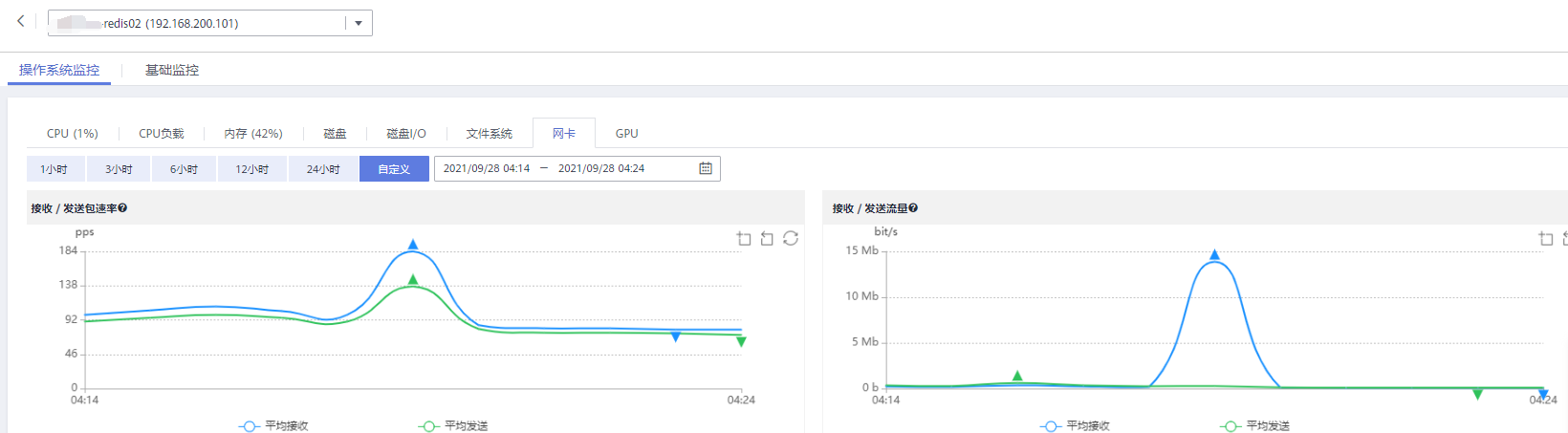
3、第3次持久化没有 Background saving terminated with success 日志,这就意味着 持久化开始没多久Redis就宕掉了;
[root@192.168.200.101]# cat /opt/redis/logs/redis_node.log | grep "28 Sep 2021"
107207:M 28 Sep 2021 04:08:42.010 * 100 changes in 300 seconds. Saving... #.第1次-RDB持久化-开始
107207:M 28 Sep 2021 04:08:42.057 * Background saving started by pid 112808
112808:C 28 Sep 2021 04:08:51.682 * DB saved on disk
112808:C 28 Sep 2021 04:08:51.737 * RDB: 14 MB of memory used by copy-on-write
107207:M 28 Sep 2021 04:08:51.890 * Background saving terminated with success #.第1次-RDB持久化-结束
107207:M 28 Sep 2021 04:13:52.069 * 100 changes in 300 seconds. Saving... #.5分钟后第2次-RDB持久化-开始
107207:M 28 Sep 2021 04:13:52.119 * Background saving started by pid 113762
113762:C 28 Sep 2021 04:14:02.159 * DB saved on disk
113762:C 28 Sep 2021 04:14:02.217 * RDB: 15 MB of memory used by copy-on-write
107207:M 28 Sep 2021 04:14:02.358 * Background saving terminated with success #.第2次-RDB持久化-结束
107207:M 28 Sep 2021 04:19:03.036 * 100 changes in 300 seconds. Saving... #.5分钟后第3次-RDB持久化-开始
107207:M 28 Sep 2021 04:19:03.086 * Background saving started by pid 114697
114697:C 28 Sep 2021 04:19:14.187 * DB saved on disk
114697:C 28 Sep 2021 04:19:14.230 * RDB: 4462 MB of memory used by copy-on-write #.第3次持久化未结束,redis就停了...
560578:C 28 Sep 2021 20:23:56.569 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
560578:C 28 Sep 2021 20:23:56.569 # Redis version=6.2.5, bits=64, commit=00000000, modified=0, pid=560578, just started
560578:C 28 Sep 2021 20:23:56.569 # Configuration loaded
560578:M 28 Sep 2021 20:23:56.569 * monotonic clock: POSIX clock_gettime
560578:M 28 Sep 2021 20:23:56.569 * Running mode=standalone, port=7100.
560578:M 28 Sep 2021 20:23:56.570 # Server initialized #.注意看下面一行的警告
560578:M 28 Sep 2021 20:23:56.570 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
560578:M 28 Sep 2021 20:23:56.570 * Reading RDB preamble from AOF file...
560578:M 28 Sep 2021 20:23:56.570 * Loading RDB produced by version 6.2.5
560578:M 28 Sep 2021 20:23:56.570 * RDB age 75576 seconds
560578:M 28 Sep 2021 20:23:56.570 * RDB memory usage when created 4306.22 Mb
560578:M 28 Sep 2021 20:23:56.570 * RDB has an AOF tail
560578:M 28 Sep 2021 20:24:02.452 * Reading the remaining AOF tail...
560578:M 28 Sep 2021 20:24:05.575 * DB loaded from append only file: 9.005 seconds
560578:M 28 Sep 2021 20:24:05.575 * Ready to accept connections
- 第2步,根据redis启动后的错误日志,看到一条告警 WARNING overcommit_memory is set to 0! Background save may fail under low memory condition.</font>,确认 overcommit_memory 值确实是为0。
[root@192.168.200.101]# cat /proc/sys/vm/overcommit_memory
0
- 第3步,查看28号凌晨4点Redis停止前后的系统日志,看到:Out of memory: Killed process 107207 (redis-server) total-vm:6018780kB,很显然是由于redis使用内存过多导致系统可用内存过低而触发了内存保护机制,系统杀掉了redis-server进程(process 107207)。
[root@192.168.200.101]# grep -i 'killed process' /var/log/messages
Sep 28 04:19:09 jjkj-sam-redis02 kernel: Out of memory: Killed process 107207 (redis-server) total-vm:6018780kB, anon-rss:4911112kB, file-rss:4kB, shmem-rss:0kB, UID:0 pgtables:11172kB oom_score_adj:0
[root@192.168.200.101]# dmesg -T | egrep "(Out of memory|oom-killer)"
[Tue Sep 28 04:18:19 2021] http-nio-8848-B invoked oom-killer: gfp_mask=0x100cca(GFP_HIGHUSER_MOVABLE), order=0, oom_score_adj=0
[Tue Sep 28 04:18:19 2021] Out of memory: Killed process 107207 (redis-server) total-vm:6018780kB, anon-rss:4911112kB, file-rss:4kB, shmem-rss:0kB, UID:0 pgtables:11172kB oom_score_adj:0
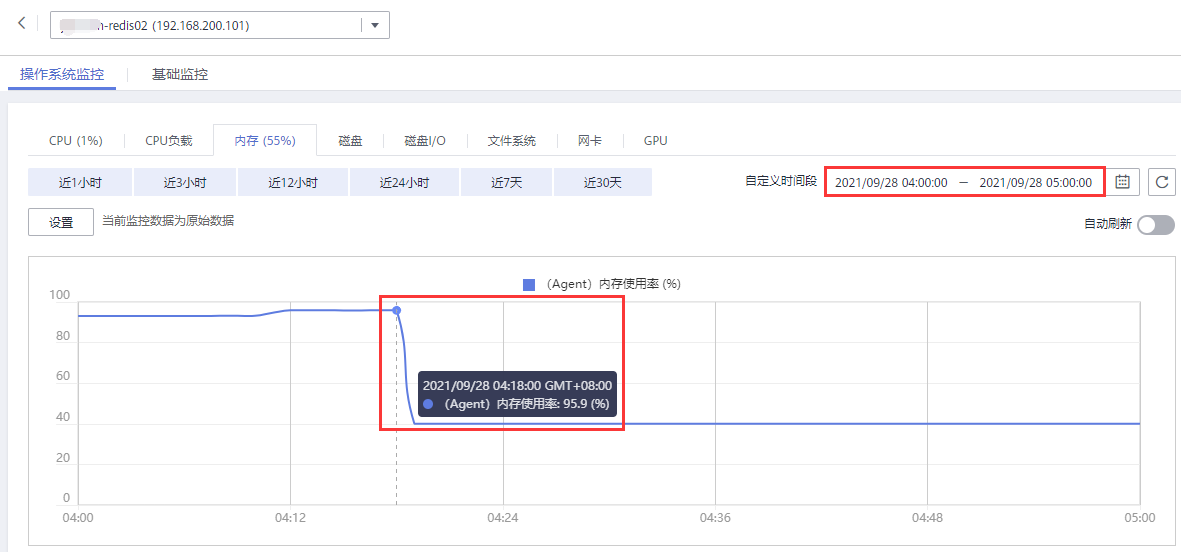
- 第4步,登录华为云监控,查看该机器在Redis停止前的内存使用率持续增长并达到95.9%
- 第5步,查看redis配置,确认没有配置maxmemory及maxmemory-policy(超过maxmemory之后的淘汰策略)
[root@192.168.200.101]# cat /opt/redis/node1_redis.conf | egrep "(maxmemory|policy)"
[root@192.168.200.101]# cat /opt/redis/node123_sentinel.conf | egrep "(maxmemory|policy)"
[root@jjkj-sam-redis02 redis]# /opt/redis/bin/redis-cli -h 127.0.0.1 -p 7100
127.0.0.1:7100> auth "***"
OK
127.0.0.1:7100> info memory
# Memory
maxmemory:0
maxmemory_policy:noeviction
- 第6步,后来从开发那里得知:27号14点开始做压测,产生的全量数据约有3.6 GB(物理内存8G,已使用95%,可用内存不足400M,而RDB持久化也需要3.6G内存),代码里设置key的过期时间为1天。
故障的原因
结合以上几点分析,总结故障原因如下:
压力测试产生大量数据,由于overcommit_memory=0,同时未设置maxmemroy及淘汰策略,导致rdb持久化的时候内存不足,从而触发系统的OOM Killer机制,最终将Redis进程杀掉。
解读:Redis 在做 RDB 快照和 AOF rewrite 时,会采用创建fork子进程的方式,把实例中的数据持久化到磁盘上。fork执行完成后,父进程和子进程会共享同一份内存数据,但此时的父进程依旧是可以接收写请求的,而新的写请求,会采用 Copy-On-Write(写时复制)的方式操作内存数据。也就是说,父进程一旦有数据需要修改,Redis 并不会直接修改共享内存的数据,而是先将被修改的内存数据复制一份,再修改这块「新申请的内存」数据,这就是所谓的「写时复制」。如果是写多读少的场景,那么在 RDB 和 AOF rewrite 期间,就会导致 Redis 父进程申请非常多的新内存。极端情况下,如果所有的共享内存都被修改,则此时Redis的内存占用将是原先的 2 倍,如果此时物理内存资源不足,这就会导致 Redis 面临被 OOM 的风险!
改进方案
- 方案1:[建议] 不做持久化,切记Redis是用来做缓存而非数据库
解读:对于数据有持久化需求的场景,建议使用MySQL进行数据存储,不要放在Redis存储
- 方案2:[建议] 设置 overcommit_memory=1
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
sysctl vm.overcommit_memory=1
cat /etc/rc.local | grep hugepage | grep enabled || echo "echo never > /sys/kernel/mm/transparent_hugepage/enabled" >> /etc/rc.local
cat /etc/rc.local | grep hugepage | grep defrag || echo "echo never > /sys/kernel/mm/transparent_hugepage/defrag" >> /etc/rc.local
- 方案3:[建议] 设置 maxmemory最大内存 + maxmemory-policy淘汰策略
解读:当redis内存数据达到maxmemory(建议设置为可用物理内存的40%)时,会根据maxmemory-policy配置来淘汰内存数据,以避免OOM。淘汰策略的选择需要结合业务特点来决定:
| 策略名 | 策略说明 | 备注 |
|---|---|---|
| noeviction | 不做任何的清理工作,超过maxmemory之后,所有的写入操作都会返回错误;但是读操作都能正常的进行 | 默认策略 |
| allkeys-random | 从所有的键中,随机选择键进行删除 | allkeys-开头的策略,即所有的键 |
| allkeys-lru | 从所有数据范围内查找到最近最少使用的键值进行淘汰,直到有足够的内存来存放新数据 | lru,least recently used,最近最少使用算法 |
| allkeys-lfu | 从所有的键中选择某段时间之内使用频次最少的键值对清除 | lfu,least frequently used,最近最不经常使用算法 |
| volatile-lru | 从设置了过期时间的键中选择最近最少使用的键值进行淘汰 | 建议策略 |
| volatile-lfu | 从设置了过期时间的键中选择某段时间之内使用频次最小的键值对清除掉 | |
| volatile-ttl | 从设置了过期时间的键中选择过期时间最早的键值对清除 | volatile-前缀的策略,即设置了过期时间的键 |
| volatile-random | 从设置了过期时间的键中,随机选择键进行清除 |
- 方案4:[建议] 添加熔断机制,若达到熔断阈值(QPS过高、服务无法响应、响应超时)时,则直接返回或从mysql取数据,不再调用Redis服务,并且还需要一个检测机制,如果Redis服务检测正常则恢复使用;
- 方案5:[建议] 增加物理内存,最佳实践是预留Redis进程1.5倍的可用内存、拒绝大字段、redis不要使用2GB以上内存;
附:更多最佳实践,请参考《Reids使用规范》
- 方案6:[不建议] 调整Redis的OOM权重,不让OS的OOM机制Kill掉Redis,但导致OOM Killer其他进程(优先kill掉 /proc/PID/oom_score 中分数越高的进程)
#查找出系统中首先会被Kill的进程
for i in /proc/*/oom_score; do pid=$(echo "${i}" | cut -d/ -f3); echo "oom_score=$(cat "${i}"), PID=${pid}, exe=$(readlink -e /proc/${pid}/exe)"; done 2> /dev/null | sort -rn -t, -k 1.11 | head -n 50