mysql开发使用规范
本规范旨在帮助开发人员逐步建立合理使用数据库的意识,对数据库相关的资源申请、业务规范使用等提供规范性的指导,从而为公司业务系统稳定、健康地运行提供保障。
以下所有规范会按照【强制】、【建议】两个级别进行标注,对于【强制】级别的设计需强制修改调整。
[TOC]
开发规范
对象命名
命名规范的对象,是指数据库SCHEMA、表TABLE、字段COLUMN、索引INDEX、约束CONSTRAINTS等
- 【强制】凡是需要命名的对象,其标识符不能超过30个字符
- 【强制】名称必须以英文字母开头,不得以 _(下划线) 作为起始和终止字母
- 【强制】所有名称的字符范围为:a-z, 0-9 和_(下划线),禁用大写、特殊符号、保留字、汉字和空格
- 【强制】所有名称统一使用小写,并采用下划线 _ 分割
- 【强制】名称应该清晰明了,能够准确表达事物的含义,最好可读,遵循“见名知意”的原则
- 【建议】数据库账户,一定要做到权限划分明确,读写账号分离,并且有辨识度,能区分具体业务
dba内部账户以dba_开头; 应用账户以user_开头:如user_upc、user_upc_r 分别代表读写、只读账号; 读写分离不提供额外账户,统一使用应用账户; 所有账户必须都在主库创建,只读查询只能从非候选上操作; - 【建议】若按日期时间分表,必须符合 _YYYY[MM][DD] 格式
- 【建议】若按HASH进行分表,库表名后缀使用十进制数,下标从0开始、下划线分隔、需要补0、每个库的表名相同,比如:
db_00{table_00 - table_31} db_01{table_00 - table_31} db_02{table_00 - table_31} db_03{table_00 - table_31} - 【建议】备份用的库、表名须以bak为前缀,以日期yyyymmdd为后缀,比如 bak_order_20160425,便于查找和知道有效期
- 【建议】临时用的库、表名须以tmp为前缀,以日期yyyymmdd为后缀,比如 tmp_order_20160425,正常业务用到的临时表、中间表,前后缀尽量不要包含 tmp 以免造成歧义
库表设计
- 【强制】生产/UAT环境建库建表,请参考《mysql建库建表规范》
- 【强制】单实例的库数量不得超过20个,再多考虑拆分实例
- 【强制】单库的表数量不得超过100个,再多考虑拆分库
- 【强制】单表的字段数量不得超过30个,再多考虑垂直分表
- 【强制】单表的数据量控制在2000万或数据容量超过10G以内,否则考虑归档或分库分表
- 【强制】单表的分表数量不得超过256个
- 【建议】如无特殊需求,必须使用Innodb存储引擎
解读:支持事务、行级锁、并发性能更好、CPU及内存缓存页优化使得资源利用率更高;
- 【建议】如无特殊需求,必须使用utf8mb4字符集,排序规则使用utf8mb4_unicode_ci
解读:万国码,无需转码,无乱码风险,节省空间,utf8mb4更可保存emoj表情(utf8不行);
- 【强制】新建的库表必须添加注释
解读:N年后鬼知道这个r1,r2,r3字段是干嘛的
- 【建议】表都必须要显式指定主键,推荐自增id主键
解读: a)主键递增,数据行写入可以提高插入性能,可避免page分裂,减少表碎片提升空间和内存的使用 b)主键要选择较短的数据类型,Innodb引擎普通索引都会保存主键的值,较短的数据类型可以有效的减少索引的磁盘空间,提高索引的缓存效率 c)无主键的表删除,在row模式的主从架构,会导致备库夯住 - 【强制】禁止使用外键,外键功能请在应用层实现
解读:外键使得表之间相互耦合,影响update/delete等SQL性能,有可能造成死锁,高并发情况下容易成为数据库瓶颈
- 【建议】日志类型的表必须提前规划轮转机制或者选择定期清理/归档 或者选择合适的db,比如hbase/mongodb
- 【建议】建议将大字段,访问频度低的字段拆分到单独的表中存储,分离冷热数据
- 【强制】数据库中不允许存储明文密码
- 【建议】如果对时间精度有要求,建表的时候请注意一下时间精度,比如 timestamp 与 timestamp(3);
- 【强制】无特殊需求,严禁使用分区表
字段设计
- 【强制】各表之间相同意义的字段必须同名
- 【建议】字段类型在满足需求条件下越小越好,使用unsigned存储非负整数 ,实际使用时候存储负数场景不多
- 【建议】数值类型优于字符类型,所以能使用数值类型的尽量不要使用字符类型
- 【强制】小数类型应选择精确度高的decimal等类型,禁止使用float和double
解读:浮点数(float和double)在存储的时候,超过指定精度后会四舍五入,这是浮点数特有的问题。因此在精度要求比较高的应用中(比如货币)要使用定点数(decimal)而不是浮点数(float和double)来保存数据。
- 【建议】合理选择char、varchar、text等字符串类型
对于长度基本固定的小字符类型,如果该列恰好更新又特别频繁,适合char 不固定长度的大字符类型,应选择varchar类型,varchar(N),N代表的是字符数,N尽可能的小 varchar虽然存储变长字符串,UTF8最多能存21844个汉字,或65532个英文 - 【强制】禁止使用BLOB和TEXT字段。如要使用,尽可能把text/blob拆到独立的表中,用PK与主表关联;
- 【强制】禁止在数据库中存储大文件,例如图片、文件等;
- 【建议】合理选择bit、int、tinyint、decimal等数字类型
使用tinyint来代替 enum和boolean 使用Decimal 代替float/double存储精确浮点数 建议使用 UNSIGNED 存储非负数值 int使用固定4个字节存储,int(11)与int(4)只是显示宽度的区别 列禁止使用bit类型,请用tinyint类型替代。bit类型加了索引可能会导致sql结果不准。 - 【建议】合理选择timestamp与datetime等时间类型
timestamp可以在insert/update行时,自动更新时间字段; 列为timestamp类型,必须指定默认值,要么current_timestamp,要么'1970-01-02 01:01:01',不要设置为''或0; 解读:DATETIME和TIMESTAMP都可用来表示YYYY-MM-DD HH:MM:SS类型的日期。两种都保存日期和时间信息,毫秒部分最高精确度都是6位数。建议使用TIMESTAMP(3)。 A. TIMESTAMP占用4字节,DATETIME占用8字节,当保存毫秒部分时两者都使用额外的空间 (1-3 字节)。 B. TIMESTAMP的取值范围比DATETIME小得多,不适合存放比较久远的日期。TIMESTAMP只能存储从 '1970-01-01 00:00:01.000000' 到 '2038-01-19 03:14:07.999999' 之间的时间。而DATETIME允许存储从 '1000-01-01 00:00:00.000000' 到 '9999-12-31 23:59:59.999999' 之间的时间。 C. TIMESTAMP的插入和查询受时区的影响。如果记录的日期需要让不同时区的人使用,最好使用 TIMESTAMP。 - 【建议】如无特殊需要,字段建议使用NOT NULL属性,可用默认值代替NULL。如果是索引字段,一定要定义为not null。因为null值会影响cordinate统计和优化器对索引的选择
- 【强制】禁止在列上配置字符集
- 【建议】使用unsigned int存储IPv4,不要使用char(15)
解读:ip转int使用 INET_ATON 函数,int转ip使用 INET_NTOA 函数,比如:select inet_aton('192.168.1.1'),inet_ntoa(3232235777);
- 【建议】使用varchar(20)存储手机号,不要使用整数
解读: 1)涉及到国家代号,可能出现+/-/()等字符,例如+86 2)手机号不会用来做数学运算 3)varchar可以模糊查询,例如 like '138%'
索引设计
- 【强制】单表索引的数量不得超过5个,否则增加维护负担、降低写入性能、占用更多空间
- 【建议】建立的索引能覆盖80%主要的查询,不求全,解决问题的主要矛盾
- 【建议】主键应选择不重复、长度小的列,没有特殊要求,使用自增id作为主键
- 【建议】自增列的名字固定为id,指定unsigned,类型2选1(int/bigint),自增列的值必须从1开始
- 【建议】主键禁止使用字符类型,禁止使用联合主键,推荐使用唯一索引来替代
- 【建议】业务上具有唯一特性的字段,必须创建唯一索引
- 【建议】不建议在频繁更新的字段上建立索引
- 【建议】索引尽量建在选择性高的列上,不在低基数列上建立索引,例如性别、类型
选择性的计算方式为: select count(distinct(col_name))/count(*) from tb_name 如果结果小于0.2,则不建议在此列上创建索引,否则大概率会拖慢SQL执行 - 【建议】合理利用覆盖索引,联合索引,避免过多的单列索引,合理使用索引来避免排序和临时表的使用
- 【建议】对超过30个字符长度的列创建索引时,考虑使用前缀索引,比如 idx_cs_guid2 (f_cs_guid(26)) 表示截取前26个字符做索引,既可以提高查找效率,也可以节省空间
解读:前缀索引的缺点是,如果在该列上 ORDER BY 或 GROUP BY 时无法使用索引,也不能把它们用作覆盖索引(Covering Index)
- 【建议】blob列不能作为key
- 【建议】bit类型字段禁止单独加索引,或者做联合索引的第一列
- 【建议】尽量使用Btree索引,不要使用其它类型索引
- 【建议】DML和order by和group by字段要建立合适的索引
关于组合索引的几点建议
- 【强制】组合索引的字段数量不得超过5个
解读:如果5个字段还不能极大缩小row范围,八成是设计有问题
- 【建议】组合索引 - 选择性高的永远在左边
- 【建议】组合索引 - 避免冗余索引,比如:(a,b,c)、(a,b)、(a),后二者为冗余索引
- 【建议】组合索引的最左匹配原则:数据库引擎使用组合索引时,从左向右(并非where条件顺序)匹配,遇到范围查询(>、<、between、like)则会停止索引匹配,无法用到后续的索引列。where条件里面字段的顺序与索引顺序无关,优化器会自动调整顺序。
比如索引idx_a_b_c(a,b,c),相当于创建了(a)、(a,b)、(a,b,c)三个索引,后二者为冗余索引: ①where a=? 用到(a) ⑦where c=? 用不到 ②where b=? and a=? 用到(a,b) ⑧where b=? and c=? 用不到 ③where a=? and c=? 用到(a) ④where a>? and b=? 用到(a) ⑤where a=? and b=? and c>? 用到(a,b,c) ⑥where a=? and b>? and c=? 用到(a,b)
SQL设计
- 【强制】禁止使用游标、存储过程、视图、触发器、自定义函数、event
解读:高并发大数据的互联网业务,架构设计思路是“解放数据库CPU,将计算转移到服务层”,并发量大的情况下,这些功能很可能将数据库拖死,业务逻辑放到服务层具备更好的扩展性,能够轻易实现“增机器就加性能”。数据库擅长存储与索引,涉及CPU计算的还是放到应用服务器上吧
- 【建议】建议将复杂的计算和逻辑操作放到程序端处理,而不是使用SQL语句处理,因为程序端方便扩容,数据库端扩容能力有限
- 【建议】数据结构设计时,可以适当设计冗余字段,减少查询的复杂度,提高查询的性能
- 【强制】禁止在数据库中存储大文件,例如图片、文件等,可以将大文件存储在对象存储系统,数据库中存储路径
- 【强制】禁止使用全文检索(Full Text Search),后续有这种需求使用搜索引擎处理
- 【强制】禁止在没有匹配索引的表上进行for update这类的操作,会锁定整个表
- 【强制】未经过DBA同意,禁止在程序端大批量更新或者删除数据,因为这样操作很可能造成复制的大量阻塞和延时,批量归档/删除,可以向dba发邮件提需求,由dba来处理
- 【强制】禁止在生产/线上环境进行代码逻辑或SQL语句性能的测试,这类操作应在开发或者测试环境进行
- 【建议】减少锁等待和竞争,避免大事务,使用短小事务
- 【建议】尽量避免使用子查询,使用join来代替
- 【强制】禁止使用order by rand()
- 【建议】多行数据需要做处理时,建议批量处理,而不是一条条来处理
- 【强制】单表的数据量控制在2000万或数据容量超过10G以内,否则考虑归档或分库分表
- 【强制】避免大表join,禁止3个大表的join,join字段类型需保持绝对一致,关联字段必须有索引
- 【建议】线上业务修改或删除数据,务必根据主键来实现
- 【建议】禁止使用 SELECT * ,必须明确指定列
- 【建议】insert必须指定字段,禁止使用 insert into xxx values()
解读:指定字段插入,在表结构变更时,能保证对应用程序无影响
- 【建议】能确定返回结果只有一条时,使用 limit 1
- 【建议】避免隐式类型转换
- 【建议】禁止在where条件列上使用函数
- 【建议】限制使用like模糊匹配,禁止使用左模糊或者全模糊,%不要放首位
- 【建议】涉及到复杂sql时,务必先参考已有索引设计,先explain
- 【建议】考虑使用union all,少使用union,注意考虑去重
- 【建议】IN的内容尽量不超过200个
- 【建议】建议在每条查询语句后面加上Limit关键字,控制返回的数据量,防止不可控的返回大量的数据
- 【建议】禁止大批量的查询数据结果,如果需要返回大量数据,请使用分页的方式处理,遇到分页有大的offset查询,可以使用延迟关联来解决
- 【建议】分页优化
SELECT * FROM tel_record t1 INNER JOIN (SELECT id FROM tel_record WHERE qiye_id = xxx ORDER BY id DESC LIMIT 999900,100) t2 ON t1.f_id = t2.f_id; 程序端保留当前页的最小id、最大id(id是主键),降序情况下,每次提取下一页的数据时,id < min_id order by id desc limit 100; 上一页 id > max_id order by id desc limit 100 - 【建议】大表count是消耗资源的操作,甚至会拖慢整个库,查询性能问题无法解决的,应从产品设计上进行重构。例如当频繁需要count的查询,考虑使用汇总表;
- 【建议】数据库的隔离级别默认为READ-COMMITTED,如不能满足业务需求,可在session层面做相应调整(必须清楚相应的隔离级别带来的锁影响)
- 【建议】数据库默认的sql_mode为严格模式(STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION),在此模式下任何不支持的语法或者数据校验不合格的,都将直接返回错误
- 【建议】日志类数据不建议存储在MySQL上,优先考虑mongodb,如需要存储请找DBA评估使用压缩表存储
- 【建议】禁止使用ENUM,可使用TINYINT代替
解读:增加新的ENUM值要做DDL操作;ENUM的内部实际存储就是整数而非字符串;
- 【建议】禁止使用OR条件,必须改为IN查询,并注意in的个数小于200
解读:旧版本mysql的OR查询是不能命中索引的,即使能命中索引,为何要让数据库耗费更多的CPU帮助实施查询优化呢? 补充:通常情况下,如果条件中有or,即使其中有条件带索引也不会使用,所以除非每个列都建立了索引,否则不建议使用OR。在多列OR中,建议用UNION ALL替换。
- 【建议】所有连接的SQL必须使用 join ... on ... 方式进行连接,而不允许直接通过普通的where条件关联方式。外连接的SQL语句,可以使用left join on的join方式,且所有外连接一律写成left join,而不要使用right join
- 【建议】避免使用否定条件。
例如,where 条件里面有<>、not in 、not exists的时候,即便是在这些判断字段上加有索引,也不会起作用。
- 【建议】有NULL值的字段查询
解读: A.不要使用count(列名)或者count(常量)来替代 count(*),count(*)是SQL92定义的标准统计行数的语法,跟数据库无关,跟null和非null无关。count(*)会统计值为null的行,而count(列名)不会统计此列为null的行。 B.count(distinct col)计算该列除null之外不重复的行数。count(distinct col1, col2),如果其中一列全为null,那么即使另一列有不同的值,也返回0 C.当某一列的值全为null,count(col)的返回结果为0,但sum(col)的返回结果为null,因此使用sum()时需要注意空指针异常的问题。可以使用ISNULL()来判断是否为NULL值: SELECT IF(ISNULL(SUM(g)), 0, SUM(g)) FROM table; - 【建议】SQL合并,主要是指的DML时候多个value合并,减少和数据库交互
使用规范
开发行为规范
- 【强制】推广活动或上线新功能必须提前通知DBA进行流量评估
- 【强制】禁止在线上环境申请个人账号,只能申请业务使用的账号
- 【强制】超过10w条的大批量更新,如修复数据、导入导出,避开高峰期,并通知DBA。可直接执行的sql由DBA操作
- 【建议】及时处理已下线业务的SQL
- 【建议】复杂sql要主动上报DBA评估,比如多表join/count/group by等
- 【建议】重要项目的数据库方案选型和设计必须提前通知DBA参与
- 【建议】对单表的多次alter操作必须合并为一次操作
- 【强制】分库分表情况下,确保所有库表字段顺序一致
- 【强制】所有数据库账号必须在主库创建
- 【强制】禁止在数据库中存放业务逻辑SQL
- 【建议】对特别重要的库表,提前与DBA沟通确定维护和备份优先级
- 【建议】维护脚本须部署在关联实例机器上,切勿乱放,比如归档,拉数据等
- 【建议】线上大批量delete和update,为了降低锁影响和减少从库延迟,必须批量执行,思路参考pt-archiver
- 【强制】线上业务不允许申请truncate、drop权限,如果需要删除表,请提交工单并由dba操作
- 【建议】线上不允许建立业务相关数据库JOB,业务逻辑在代码层实现
- 【建议】线上不允许使用长事务,慎用set autocommit=0或者begin,推荐使用set autocommit=1,
超时5秒的事务,DBA JOB会自动kill
线上变更规范
- 【强制】生产系统变更数据,请参考《线上变更规范》
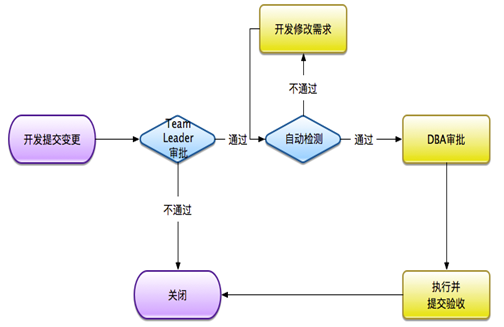
- 【建议】数据变更流程,可参考下图: