sqlserver字符集与排序规则
概述
- 字符串的物理存储由排序规则控制,排序规则指定表示每个字符的位模式以及存储和比较字符所使用的规则,它不仅影响记录行的sort顺序,还影响中文显示是否乱码等。
- sqlserver排序规则的名称由两部分构成,前半部分是指本排序规则所支持的字符集,比如
Chinese_PRC,而后半部分即后缀含义,主要包括如下:
_BIN 二进制排序
_CI(CS) 是否区分大小写,CI不区分,CS区分(case-insensitive/case-sensitive)
_AI(AS) 是否区分重音,AI不区分,AS区分(accent-insensitive/accent-sensitive),比如 a 不等同于 á
_KI(KS) 是否区分假名类型,KI不区分,KS区分(kanatype-insensitive/kanatype-sensitive)
_WI(WS) 是否区分宽度,WI不区分,WS区分(width-insensitive/width-sensitive),比如 半角 与 全角
- 比如:Chinese_PRC_CI_AS,其中 Chinese_PRC 指针对大陆简体字UNICODE的字符集,CI_AS 指的是 CI不区分大小写、AS区分重音
- sqlserver排序规则的优先级,从低到高分为3个级别:实例级别、db库级别、字段级别,即创建db时若未指定排序规则,则继承实例级别的排序规则
- 正确的设置SQL Server排序规则,保持 Instance、Database、Column 这3处的排序规则一致,默认排序规则是 Chinese_PRC_CI_AS
如何确认
- 查看当前sql所支持的所有排序规则:
SELECT * FROM ::fn_helpcollations() - 查看实例的排序规则:
SELECT SERVERPROPERTY ('Collation') - 查看所有库的排序规则:
SELECT name, collation_name FROM sys.databases - 查看某表字段的排序规则:
SELECT name,collation FROM sys.syscolumns WHERE collation IS NOT NULL
--.创建测试表
CREATE TABLE xxx1(col1 nvarchar(4) collate Latin1_General_CI_AS, col2 varchar(20) collate Chinese_PRC_CI_AS)
--.查看特定/所有表的字段排序规则,仅限字符型,包括 varchar+char+nvarchar+nchar
SELECT
db_name() as database_name
,sch.name AS schema_name
,obj.name AS table_name
,col.name AS column_name
,typ.name AS column_type
,col.prec AS column_length
,CASE WHEN col.isnullable=0 THEN 'NOT NULL' ELSE 'NULL' END AS column_isnull
,col.collation
FROM sys.objects AS obj
INNER JOIN sys.schemas AS sch ON obj.schema_id = sch.schema_id
LEFT JOIN sys.syscolumns AS col ON obj.object_id = col.id
LEFT JOIN sys.types AS typ ON col.xtype=typ.user_type_id
WHERE obj.type = 'U' AND typ.user_type_id IN (167,175,231,239) --filter: varchar+char+nvarchar+nchar
AND obj.name = 'xxx' --只看xxx表
如何修改
- 安装SQLServer的时候,指定实例的排序规则,示例指定
Chinese_PRC_CI_AS
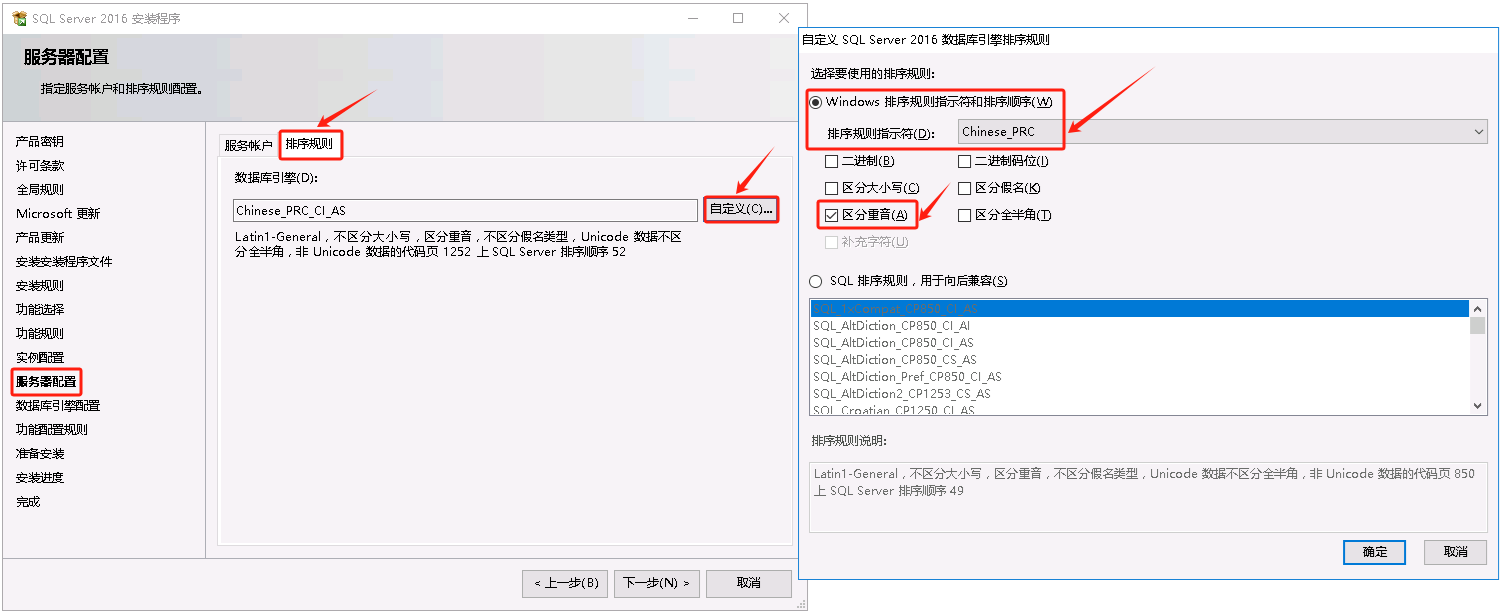
- 更改实例的排序规则,示例改为 `Chinese_PRC_CI_AS`,其中 `WIN2016` 为主机名、`WMS` 为非默认的命名实例(默认实例请改为`MSSQLSERVER`)
- 注:操作之前务必备份login和job、同时建议停掉SQLServer服务,重建数据库之后 login、db、job 将会消失(用户db需手动附加一下,login和job需通过脚本创建)
cd /d {SQL安装路径}
SQL2008安装路径:C:\Program Files\Microsoft SQL Server\100\Setup Bootstrap\Release
SQL2012安装路径:C:\Program Files\Microsoft SQL Server\110\Setup Bootstrap\SQLServer2012
SQL2014安装路径:C:\Program Files\Microsoft SQL Server\120\Setup Bootstrap\SQLServer2014
SQL2016安装路径:C:\Program Files\Microsoft SQL Server\130\Setup Bootstrap\SQLServer2016
set my_SVRADMIN=WIN2016\administrator
set my_INSTNAME=WMS
set my_SAPWD=Admin_147
set my_COLLATION=Chinese_PRC_CI_AS
setup /QUIET /ACTION=REBUILDDATABASE /INSTANCENAME="%my_INSTNAME%" /SQLSYSADMINACCOUNTS="%my_SVRADMIN%" /SAPWD="%my_SAPWD%" /SQLCOLLATION="%my_COLLATION%"
- 建库的时候,指定数据库的排序规则:
CREATE DATABASE xxx COLLATE Latin1_General_CI_AS - 修改数据库的排序规则:
ALTER DATABASE xxx COLLATE Chinese_PRC_CI_AS - 建表的时候,指定表字段的排序规则:
CREATE TABLE xxx2(name nvarchar(4) COLLATE Latin1_General_CI_AS) - 修改表字段的排序规则:
ALTER TABLE xxx2 ALTER COLUMN name nvarchar(4) COLLATE Chinese_PRC_CI_AS NULL
关于修改字段排序规则的几点说明
- COLLATE 子句 只能用来更改数据类型为 char、varchar、nchar 和 nvarchar 的列的排序规则
- 不能更改的列包括:主键、唯一约束、FOREIGN KEY 约束、已为列创建了索引、统计信息或全文检索
不可变更字段的排序规则的场景
- 场景1:字段有索引
--.若该字段有任何索引,则更改排序规则会报错 由于一个或多个对象访问此 列,ALTER TABLE ALTER COLUMN col1 失败。
DROP TABLE xxx
CREATE TABLE xxx(col1 varchar(10) COLLATE Latin1_General_CI_AS, col2 varchar(20))
CREATE INDEX idx_col1 ON xxx(col1)
ALTER TABLE xxx ALTER COLUMN col1 varchar(10) COLLATE Chinese_PRC_CS_AI
--.可以先删掉索引,再修改排序规则,最后再添加主键
DROP INDEX idx_col1 ON xxx
ALTER TABLE xxx ALTER COLUMN col1 varchar(10) COLLATE Chinese_PRC_CS_AI
CREATE INDEX idx_col1 ON xxx(col1)
- 场景2:字段有主键
--.若该字段有主键约束,则更改排序规则会报错 由于一个或多个对象访问此 列,ALTER TABLE ALTER COLUMN col1 失败。
DROP TABLE xxx
CREATE TABLE xxx(col1 varchar(10) COLLATE Latin1_General_CI_AS NOT NULL, col2 varchar(20))
ALTER TABLE xxx ADD CONSTRAINT pk_xxx PRIMARY KEY CLUSTERED (col1)
ALTER TABLE xxx ALTER COLUMN col1 varchar(10) COLLATE Chinese_PRC_CS_AI
--.可以先删掉主键,再修改排序规则,最后再添加主键
ALTER TABLE xxx DROP CONSTRAINT pk_xxx
ALTER TABLE xxx ALTER COLUMN col1 varchar(10) COLLATE Chinese_PRC_CS_AI NOT NULL
ALTER TABLE xxx ADD CONSTRAINT pk_xxx PRIMARY KEY CLUSTERED (col1)
- 场景3:字段有唯一约束索引
--.若该字段有唯一约束索引,可以参考主键的处理办法
DROP INDEX UQ_PayOrder_MerchantTradeNo ON PayOrder
ALTER TABLE PayOrder ALTER COLUMN MerchantTradeNo nvarchar(30) COLLATE Chinese_PRC_CS_AS NOT NULL
CREATE UNIQUE NONCLUSTERED INDEX IX_UQ_PayOrder_MerchantTradeNo ON PayOrder(MerchantTradeNo) WITH(ONLINE = ON,FILLFACTOR=90)
遇到的问题
场景1:排序规则不一致导致sql执行报错
- 用于join的字段的排序规则如果不一致,则会报错 无法解决 equal to 运算中 "xxx" 和 "yyy" 之间的排序规则冲突,场景重现如下:
IF OBJECT_ID('tb1') IS NOT NULL
DROP TABLE tb1
IF OBJECT_ID('tb2') IS NOT NULL
DROP TABLE tb2
CREATE TABLE tb1(col1 varchar(1), col2 varchar(20) collate Chinese_PRC_CS_AS)
CREATE TABLE tb2(col1 varchar(1), col2 varchar(20) collate Chinese_PRC_CI_AS)
CREATE UNIQUE NONCLUSTERED INDEX IX_UQ_tb1_col2 ON tb1(col2) WITH(ONLINE = ON)
CREATE UNIQUE NONCLUSTERED INDEX IX_UQ_tb2_col2 ON tb2(col2) WITH(ONLINE = ON)
INSERT INTO tb1 VALUES('a','hello')
INSERT INTO tb1 VALUES('b','HELLO')
INSERT INTO tb2 VALUES('a','hello')
GO
--.报错1:不能在具有唯一索引“IX_UQ_tb2_col2”的对象“dbo.tb2”中插入重复键的行。重复键值为 (HELLO)。
INSERT INTO tb2 VALUES('b','HELLO')
--.下面的不报错
SELECT t1.* FROM tb1 t1 INNER JOIN tb2 t2 on t1.col1 = t2.col1
--.报错2:无法解决 equal to 运算中 "Chinese_PRC_CI_AS" 和 "Chinese_PRC_CS_AS" 之间的排序规则冲突。
SELECT t1.* FROM tb1 t1 INNER JOIN tb2 t2 on t1.col2 = t2.col2