[草稿] 浅谈NUMA架构与数据库
在安装 MySQL 或 SQL Server 前配置服务器环境时,针对是否要配置numa的疑虑,本文进行了关于 numa 的研究。
[TOC]
NUMA 简介
为什么要有NUMA
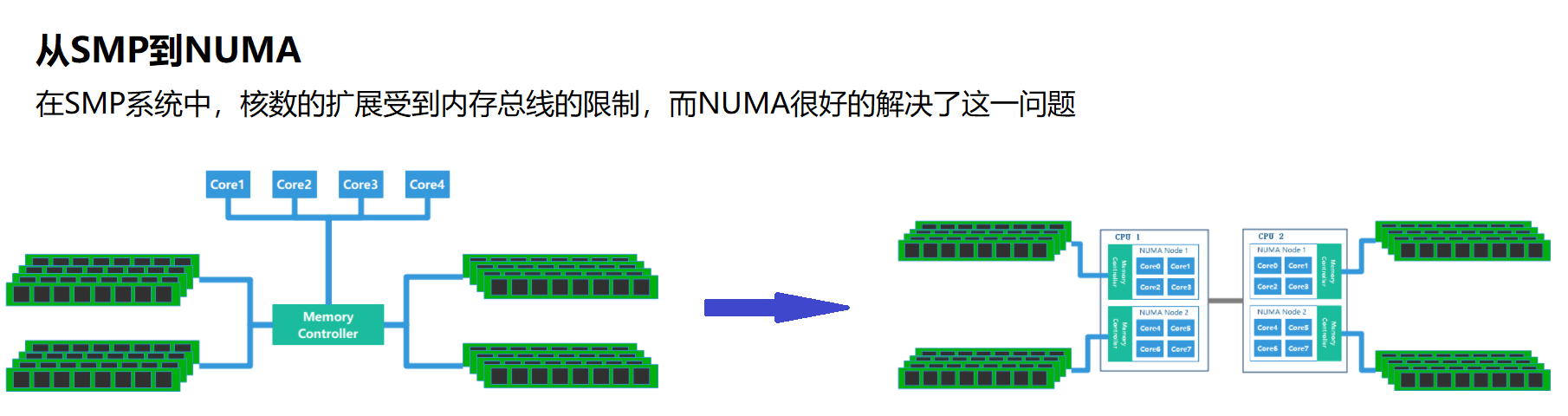
早期的计算机系统一直处于硬件资源匮乏的阶段,CPU、内存都是十分稀缺的资源,因此在发展SMP架构(Symmetric Multi-Processor,对称多处理器结构)的系统的时候,早期都是使用UMA(Uniform Memory Access,一致存储访问结构)的架构的,所有的CPU访问内存的时候都是通过北桥的总线控制器统一访问内存。
由于所有CPU Core都是通过共享一个北桥来读取内存,在只有一两颗CPU,几百M内存的服务器上,这一切都不是问题,但随着CPU和内存越来越多,导致多核CPU通过一条总线共享内存成为瓶颈,于是NUMA(Non-Uniform Memory Access,非一致存储访问结构)出现了。
NUMA特点
- CPU平均划分为若干个Chip(不多于4个),每个Chip有自己的内存控制器及内存插槽
- CPU访问自己Chip上所插的内存(Local Access)时速度快,而访问其他CPU所关联的内存(Remote Access)的速度相较慢三倍左右
- 默认的内存分配方案:优先尝试在请求线程当前所处的CPU的Local内存上分配空间,如果local内存不足,优先淘汰local内存中无用的Page
- 于是Linux内核默认使用CPU亲和的内存分配策略,使内存页尽可能的和调用线程处在同一个Core/Chip中
- 由于内存页没有动态调整策略,使得大部分内存页都集中在
CPU 0上 - 又因为
Reclaim默认策略优先淘汰/Swap本Chip上的内存,使得大量有用内存被换出 - 当被换出页被访问时,问题就以数据库响应时间飙高甚至阻塞的形式出现了
NUMA的内存分配策略
- 1.缺省(default):总是在本地节点分配(分配在当前进程运行的节点上)
- 2.绑定(bind):强制分配到指定节点上
- 3.交叉(interleave):在所有节点或者指定的节点上交织分配
- 4.优先(preferred):在指定节点上分配,失败则在其他节点上分配
因为NUMA默认的内存分配策略(default)是优先在进程所在CPU的本地内存中分配,会导致CPU节点之间内存分配不均衡,当某个CPU节点的内存不足时,会导致swap产生,而不是从远程节点分配内存。这就是所谓的swap insanity 现象。
NUMA 配置
安装numactl工具
Linux提供了一个手工调优的命令numactl(默认不安装)
yum install -y numactl
确认numa信息
- 查看
/proc/cmdline若有numa=off则表示已关闭 numa
cat /proc/cmdline | grep -i numa
- 执行
numactl --show查看当前系统numa策略
[root@u-228234-wiki ~]# numactl --show
policy: default
preferred node: current
physcpubind: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
cpubind: 0 1
nodebind: 0 1
membind: 0 1
- 执行
numastat查看
# numastat
node0 node1
numa_hit 1296554257 918018444
numa_miss 8541758 40297198
numa_foreign 40288595 8550361
interleave_hit 45651 45918
local_node 1231897031 835344122
other_node 64657226 82674322
说明:
- numa_hit—命中的,也就是为这个节点成功分配本地内存访问的内存大小
- numa_miss—把内存访问分配到另一个node节点的内存大小,这个值和另一个node的numa_foreign相对应。
- numa_foreign–另一个Node访问我的内存大小,与对方node的numa_miss相对应
- local_node----这个节点的进程成功在这个节点上分配内存访问的大小
- other_node----这个节点的进程 在其它节点上分配的内存访问大小
很明显,miss值和foreign值越高,就要考虑绑定的问题。
- 执行
numactl --hardware列举系统上的NUMA节点
[root@u-228234-wiki ~]# numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30
node 0 size: 64337 MB
node 0 free: 1263 MB
node 1 cpus: 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31
node 1 size: 64509 MB
node 1 free: 30530 MB
node distances:
node 0 1
0: 10 21
1: 21 10
从上面的返回可以看到:
- cpu0 可用 内存 1263 MB
- cpu1 可用内存 30530 MB
当cpu0上申请内存超过1263M时必定使用swap,这个是很不合理的。
这里假设我要执行一个java param命令,此命令需要1G内存;一个python param命令,需要8G内存。
最好的优化方案时python在node1中执行,而java在node0中执行,那命令是:
numactl --cpubind=0 --membind=0 python param
numactl --cpubind=1 --membind=1 java param
xxxxxxxxxxxxxxxxxxxxx
举例:
# numactl --hardware
node 0 cpus: 0 2 4 6
node 0 size: 65490 MB
node 0 free: 24447 MB
node 1 cpus: 1 3 5 7
node 1 size: 65536 MB
node 1 free: 16050 MB
node distances:
node 0 1
0: 10 20
1: 20 10
可以看到numa节点是2个,cpu物理节点是8个。现在我们绑定资源,两颗cpu,每颗4个物理节点,那么我们开4个mysql实例,每个实例绑定2个cpu物理节点
numactl --physcpubind=0,3 --localalloc mysqld_multi --defaults-extra-file=/etc/mysqld_multi.cnf start 1
- -–physcpubind 指定绑定的cpu节点,
- -–localalloc表示使用内存方式,不交叉,以免降低性能,
- mysqld_multi是mysql实例启动命令
其他
调整vm.swappiness内核参数
vm.swappiness控制Linux物理内存进行swap页交换的相对权重,尽量减少系统的页缓存被从内存中清除的情况。取值范围是0~100,vm.swappiness的值越低,Linux内核会尽量不进行swap交换页的操作。 默认60,即当系统需要内存时,有60%的概率使用swap;对于大多数桌面系统,设置为100可以提高系统的整体性能;对于数据库应用服务器,设置为0,可以提高物理内存的使用率,进而提高数据库服务的响应性能。
echo "vm.swappiness = 1" >> /etc/sysctl.conf
sysctl -p
sysctl -a | grep swap
- 参考:https://www.cnblogs.com/lyhabc/archive/2013/02/05/2892470.html
- 参考:https://www.cnblogs.com/lyhabc/archive/2012/10/17/2728724.html
numad服务
在redhat6中,有一个numad的服务(需手工安装),它可以自动的监控我们cpu状况,并自动平衡资源,这个服务需要在内存使用量非常大的时候才会有明显的效果,当内存空余量较大时,需要关闭KSM,避免发生冲突。官方说在某些内存使用巨大的环境中,可能会提高50%的性能。
service numad start
如何关闭NUMA
方式1、硬件层,在 BIOS 中设置关闭
BIOS:interleave = Disable / Enable
方式2、OS内核层,在 Linux Kernel 启动参数中加上 numa=off 后 reboot 重启服务器
For RHEL 6
编辑 /boot/grub/grub.conf 在 kernel 行加上 numa=off
# vi /boot/grub/grub.conf
kernel /vmlinuz-2.6.39-400.215.10.EL ro root=/dev/VolGroup00/LogVol00 numa=off
For RHEL 7
编辑 /etc/default/grub 加上 numa=off 并重建 GRUB 配置文件生效
sed -i 's/quiet/quiet numa=off/' /etc/default/grub
grub2-mkconfig -o /etc/grub2.cfg
重启后,通过以下命令可以查看是否成功关闭(若关闭则返回numa=off):
dmesg | grep -i numa
cat /proc/cmdline | grep -i numa
方式3、数据库层,在 mysqld_safe 脚本中加上 numactl --interleave=all 强制启动MySQL的时候,关闭NUMA特性
# numactl --interleave=all mysqld_safe --defaults-file=/etc/my.cnf &
NUMA与数据库的最佳实践
MySQL 建议关闭numa
NUMA 与 MySQL 分析
MySQL 数据库是单进程多线程的架构,在开启的 NUMA 服务器中,内存被分配到各 NUMA Node 上,而 MySQL 进程只能消耗所在节点的内存。所以在开启 NUMA 的服务器上,某些特殊场景中容易出现系统拥有空闲内存但发生 SWAP 导致性能问题的情况。
比如专用的 MySQL 单实例服务器,物理内存为 40GB,MySQL 进程所在节点的本地内存为 20G,而 MySQL 配置 30GB 内存,超出节点本地内存部分会被 SWAP 到磁盘上,而不是使用其他节点的物理内存,引发性能问题。
修改numa以及IO调度对mysql的提升
三个解决方案
numactl --interleave=all- 在MySQL进程启动前,使用
sysctl -q -w vm.drop_caches=3清空文件缓存所占用的空间 - Innodb在启动时,就完成整个Innodb_buffer_pool_size的内存分配
不过这种三合一的解决方案,只是减少了NUMA内存分配不均导致的MySQL SWAP问题出现的可能性。如果当系统上其他进程,或者MySQL本身需要大量内存时,Innodb Buffer Pool的那些Page同样还是会被Swap到存储上。
在此基础上的四个进阶方案
- 配置
vm.zone_reclaim_mode = 0使得内存不足时去remote memory分配优先于swap out local page
echo -15 > /proc/<pid_of_mysqld>/oom_adj
- 调低MySQL进程被OOM_killer强制Kill的可能
- memlock
- 对MySQL使用Huge Page(黑魔法,巧用了Huge Page不会被swap的特性)
为什么Interleave的策略就解决了问题?
- 几乎所有情况下Interleave模式下的程序性能都要比默认的亲和模式要高,有时甚至能高达30%。
- 究其根本原因是Linux服务器的大多数workload分布都是随机的:即每个线程在处理各个外部请求对应的逻辑时,所需要访问的内存是在物理上随机分布的。
- 而Interleave模式就恰恰是针对这种特性将内存page随机打散到各个CPU Core上,使得每个CPU的负载和Remote Access的出现频率都均匀分布。
- 相较NUMA默认的内存分配模式,死板的把内存都优先分配在线程所在Core上的做法,显然普遍适用性要强很多。
- 像MySQL这种外部请求随机性强,各个线程访问内存在地址上平均分布的这种应用,Interleave的内存分配模式相较默认模式可以带来一定程度的性能提升。
真正造成程序在NUMA系统上性能瓶颈的并不是Remote Acess带来的响应时间损耗,而是内存的不合理分布导致Remote Access将inter-connect这个小水管塞满所造成的结果。 而Interleave恰好,把这种不合理分布情况下的Remote Access请求平均分布在了各个小水管中。所以这也是Interleave效果奇佳的一个原因。
MySQL在NUMA架构上会出现的问题
- The MySQL “swap insanity” problem and the effects of the NUMA architecture
- A brief update on NUMA and MySQL
- MySQL – The MySQL “swap insanity” problem and the effects of the NUMA architecture
- PostgreSQL – PostgreSQL, NUMA and zone reclaim mode on linux
- Oracle – Non-Uniform Memory Access (NUMA) architecture with Oracle database by examples
- Java – Optimizing Linux Memory Management for Low-latency / High-throughput Databases
- 关于numa 内存分配不平均导致mysql 阻塞
innodb_numa_interleave 参数
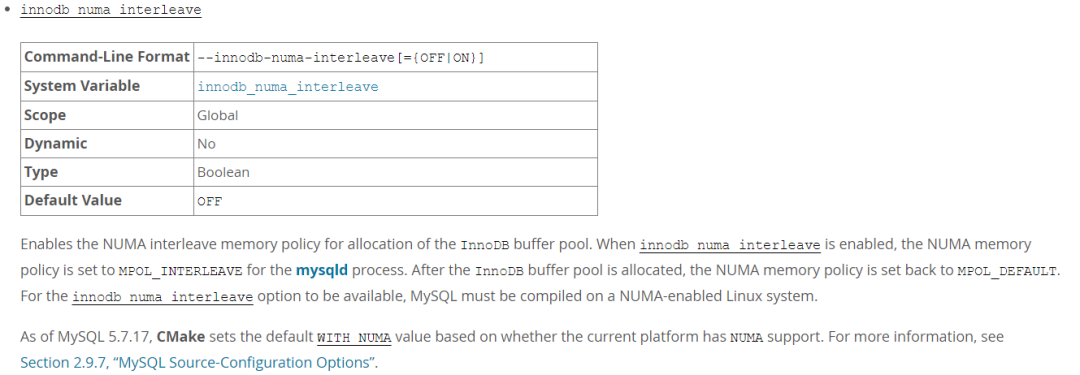
MySQL 在 5.6.27、5.7.9 引入了 innodb_numa_interleave 参数,MySQL 自身解决了内存分类策略的问题,需要服务器支持 numa。
根据官方文档的描述:
- 当启用 innodb_numa_interleave 时,mysqld 进程的 NUMA 内存策略被设置为 MPOL_INTERLEAVE,当 InnoDB 缓冲池分配完毕后,NUMA 内存策略又被设置为 MPOL_DEFAULT。
- 当然 innodb_numa_interleave 参数生效,MySQL 必须是在启用 NUMA 的 Linux 系统上编译安装。
- 从 MySQL 5.7.17 开始,CMake 编译软件新增了 WITH_NUMA 参数,可以在支持 NUMA 的 Linux 系统上编译 MySQL。
经过测试:
- 1.若系统不支持 NUMA,
-DWITH_NUMA=ON会导致 CMake 编译失败; - 2.参数 innodb_numa_interleave 在 MySQL 5.7.17 的免编译的二进制包中是不支持的;
- 3.从 MySQL 5.7.19+ 的免编译的二进制包才开始支持 innodb_numa_interleave 参数;
关于 NUMA 的建议
- 若是专用的 MySQL 服务器,可以直接在 BIOS 层或者 OS 内核层关闭 NUMA;
- 若希望其他进程使用 NUMA 特性,可以选择合适的 MySQL 版本开启 innodb_numa_interleave 参数。
SQLServer 建议开启numa
从 SQL Server 2000 SP3 以后,SQL Server开始支持NUMA架构,内存访问会尽量使用离CPU最近的内存,以提高性能。
--.如果仅返回一个内存节点(节点0),则表示已禁用NUMA.
SELECT memory_node_id,COUNT(1) AS node_counts
FROM sys.dm_os_memory_clerks
WHERE memory_node_id <> 64
GROUP BY memory_node_id
ORDER BY memory_node_id
--.查看NUMA信息.
DECLARE @errorlog TABLE(logdate datetime,info varchar(20),text nvarchar(max))
INSERT INTO @errorlog EXEC sys.xp_readerrorlog 0,1,Null,Null,'2010-07-23',NULL,'DESC'
SELECT * FROM @errorlog WHERE text LIKE '%NUMA%'
Mongodb 建议关闭numa
内核优化
echo 0 | sudo tee /proc/sys/vm/zone_reclaim_mode sudo sysctl -w vm.zone_reclaim_mode=0启动脚本,加上
numactl --interleave=all
结论
| 数据库 | 推荐设置 | 备注 |
|---|---|---|
| MySQL | 禁用numa | xxx |
| Redis | xxx | xxx |
| Mongodb | 禁用numa | xxx |
| SQL Server | 开启numa | 微软官方建议 |
| PostgreSQL | xxx | xxx |
几个误区
误区1、numactl 命令未找到,numa 就是未开启吗?
答:不是,numactl 是 Linux 提供的一个对 NUMA 进行手工调优的命令(默认不安装),可以用 numactl 命令查看系统的 NUMA 状态和对 NUMA 进行控制。