分库分表最佳实践
关系型数据库本身比较容易成为系统瓶颈,单机存储容量、连接数、处理能力都有限。当单表的数据量达到1000W或100G以后,由于查询维度较多,即使添加从库、优化索引,做很多操作时性能仍下降严重。
分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来独立的数据库拆分成若干数据库组成 ,将数据大表拆分成若干数据表组成,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。
[TOC]
一、前言
中大型项目中,一旦遇到数据量比较大,小伙伴应该都知道就应该对数据进行拆分了。有垂直和水平两种。
垂直拆分
一个数据库由多个表构成,每个表对应不同的业务,垂直切分是指按照业务将表进行分类,将其分布到不同的数据库上,这样就将数据分担到了不同的库上(专库专用),用于分解单库单表的压力。
如下图,垂直切分就是根据每个表的不同业务进行切分,比如订单表、用户表,将每个表切分到不同的数据库上。
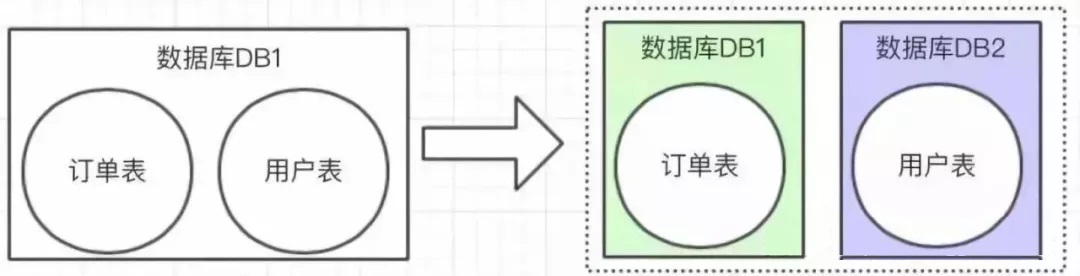
垂直切分的优点如下:
- 拆分后业务清晰,拆分规则明确;
- 系统之间进行整合或扩展很容易;
- 按照成本、应用的等级、应用的类型等将表放到不同的机器上,便于管理;
- 便于实现动静分离、冷热分离的数据库表的设计模式;
- 数据维护简单;
垂直切分的缺点如下:
- 部分业务表无法join关联,只能通过接口方式解决,提高了系统的复杂度;
- 受每种业务的不同限制,存在单库性能瓶颈,不易进行数据扩展和提升性能;
- 事务处理复杂;
水平拆分
与垂直切分对比,水平切分不是将表进行分类,而是将其按照某个字段的某种规则分散到多个库中,在每个表中包含一部分数据,所有表加起来就是全量的数据。
这种切分方式根据单表的数据量的规模来切分,保证单表的容量不会太大,从而保证了单表的查询等处理能力,例如将订单表拆分成 order_1、order_2 等,表结构是完全一样的。
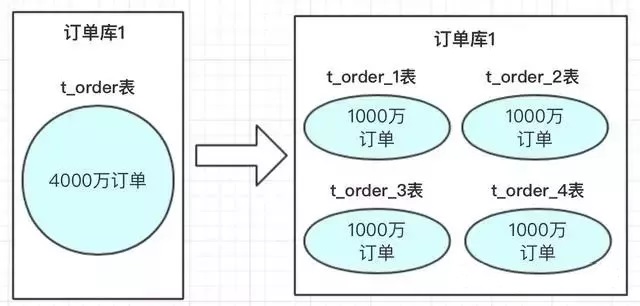
上图中订单数据达到了4000万,我们也知道mysql单表存储量推荐是百万级,如果不进行处理,mysql单表数据太大,会导致性能变慢。
水平切分的优点如下:
- 单库单表的数据保持在一定的量级,有助于性能的提高。
- 切分的表的结构相同,应用层改造较少,只需要增加路由规则即可。
- 提高了系统的稳定性和负载能力。
水平切分的缺点如下:
- 切分后,数据是分散的,很难利用数据库的Join操作,跨库Join性能较差。
- 拆分规则难以抽象。
- 分片事务的一致性难以解决。
- 数据扩容的难度和维护量极大。
综上所述,垂直切分和水平切分的共同点如下:
- 存在分布式事务的问题。
- 存在跨节点Join的问题。
- 存在跨节点合并排序、分页的问题。
- 存在多数据源管理的问题。
在了解这两种切分方式的特点后,我们就可以根据自己的业务需求来选择,通常会同时使用这两种切分方式,垂直切分更偏向于业务拆分的过程,在技术上我们更关注水平切分的方案。
二、分库分表方案
分库分表方案中有常用的方案,hash取模和range范围方案;分库分表方案最主要就是路由算法,把路由的key按照指定的算法进行路由存放。下边来介绍一下两个方案的特点。
hash取模方案
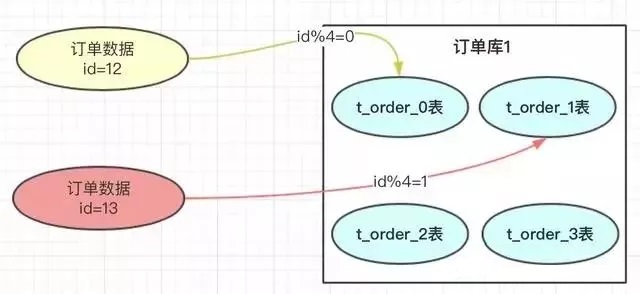
在我们设计系统之前,可以先预估一下大概这几年的订单量,如:4000万。每张表我们可以容纳1000万,也我们可以设计4张表进行存储。
那具体如何路由存储的呢?
hash的方案就是对指定的路由key(比如id)对分表总数进行取模,上图中,id=12的订单,对4进行取模,也就是会得到0,那此订单会放到0表中。id=13的订单,取模得到为1,就会放到1表中。为什么对4取模,是因为分表总数是4。
优点:
订单数据可以均匀的放到那4张表中,这样此订单进行操作时,就不会有热点问题。
热点的含义:热点的意思就是对订单进行操作集中到1个表中,其他表的操作很少。
订单有个特点就是时间属性,一般用户操作订单数据,都会集中到这段时间产生的订单。如果这段时间产生的订单 都在同一张订单表中,那就会形成热点,那张表的压力会比较大。
缺点:
将来的数据迁移和扩容会很难。
比如:业务发展很好,订单量很大,超出了4000万的量,那我们就需要增加分表数。如果我们增加4个表:
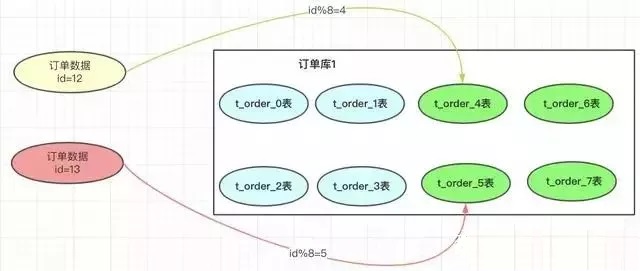
一旦我们增加了分表的总数,取模的基数就会变成8,以前id=12的订单按照此方案就会到4表中查询,但之前的此订单时在0表的,这样就导致了数据查不到。就是因为取模的基数产生了变化。
挑战:
遇到这个情况,我们小伙伴想到的方案就是做数据迁移,把之前的4000万数据,重新做一个hash方案,放到新的规划分表中。也就是我们要做数据迁移。这个是很痛苦的事情。有些小公司可以接受晚上停机迁移,但大公司是不允许停机做数据迁移的。
当然做数据迁移可以结合自己的公司的业务,做一个工具进行,不过也带来了很多工作量,每次扩容都要做数据迁移。
那有没有不需要做数据迁移的方案呢,我们看下面的方案:
range范围方案
range方案也就是以范围进行拆分数据。
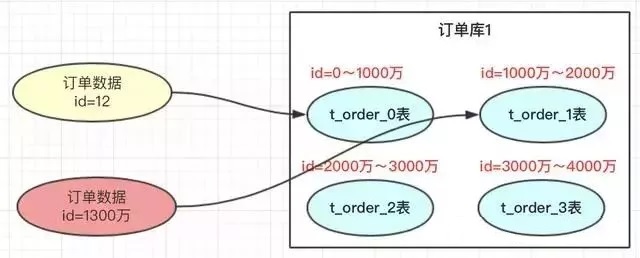
range方案比较简单,就是把一定范围内的订单,存放到一个表中;如上图id=12放到0表中,id=1300万的放到1表中。设计这个方案时就是前期把表的范围设计好,通过id进行路由存放。
优点:
此方案因为不需要迁移老数据,所以扩容特别方便。即时再增加4张表,之前的4张表的范围不需要改变,id=12的还是在0表,id=1300万的还是在1表,新增的4张表的范围肯定是 大于 4000万的。
缺点:
此方案有热点问题,因为id的值会一直递增变大,某段时间产生的订单一直在某一张表中,比如id在【1000万~2000万】的订单,这个就导致1表过热,压力过大,而其他的表没有什么压力。
总结
- hash取模方案:没有热点问题,但扩容迁移数据很痛苦
- range方案:不需要迁移数据,但有热点问题
那有什么方案可以做到hash和range的优点结合呢?即不需要迁移数据,又能解决数据热点的问题呢?
其实还有一个现实需求,能否根据服务器的性能以及存储高低,适当均匀调整存储呢?
三、方案思路
hash是可以解决数据均匀的问题,range可以解决数据迁移问题,那我们可以不可以两者相结合呢?利用这两者的特性呢?
我们考虑一下数据的扩容代表着,路由key(如id)的值变大了,这个是一定的,那我们先保证数据变大的时候,首先用range方案让数据落地到一个范围里面。这样以后id再变大,那以前的数据是不需要迁移的。
但又要考虑到数据均匀,那是不是可以在一定的范围内数据均匀的呢?因为我们每次的扩容肯定会事先设计好这次扩容的范围大小,我们只要保证这次的范围内的数据均匀是不是就ok了。
四、方案设计
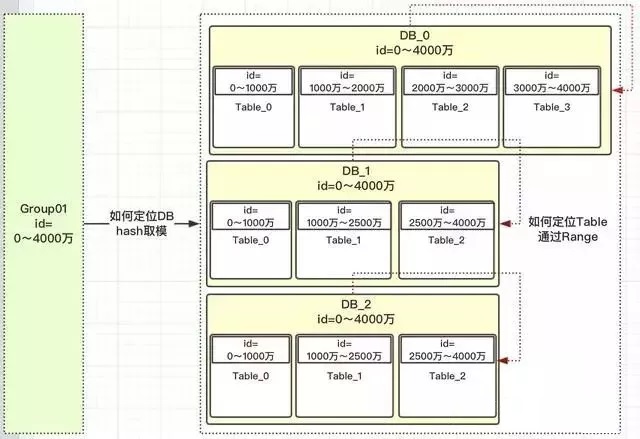
我们先定义一个group组概念,这组里面包含了一些分库以及分表,如下图:
上图有几个关键点:
- id=0~4000万肯定落到group01组中。
- group01组有3个DB,那一个id如何路由到哪个DB?
- 根据hash取模定位DB,那模数为多少?模数要为此group组所有DB中表的总数,上图总表数为10
问题来了:
- 问题1:为什么要取表的总数10?而不是DB总数3呢?
- 问题2:若id=12,id%10=2,那落到哪个DB库呢?
- 问题3:定位哪个DB后,那落到该DB中的哪张表呢?
五、核心主流程
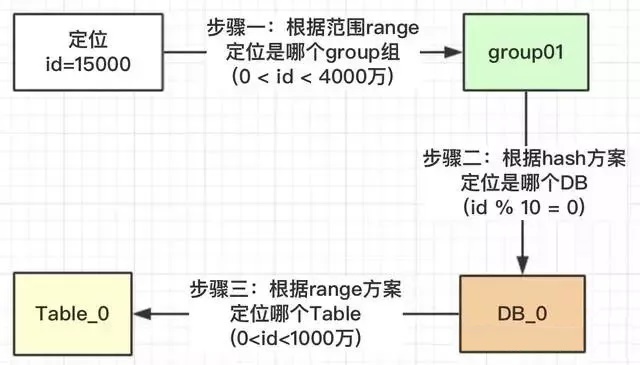
按照上面的流程,我们就可以根据此规则,定位一个id,我们看看有没有避免热点问题。
我们看一下,id在【0~1000万】范围内的,根据上面的流程设计,1000万以内的id都均匀的分配到DB_0,DB_1,DB_2三个数据库中的Table_0表中,为什么可以均匀,因为我们用了hash的方案,对10进行取模。这也回答了上面的问题1“为什么对表的总数10取模,而不是DB的总数3进行取模?”
我们看一下为什么DB_0是4张表,其他两个DB_1是3张表?
在我们安排服务器时,有些服务器的性能高、空间大,就可以安排多存放些数据,有些性能低的就少放点数据。如果我们取模是按照DB总数3,进行取模,那就代表着【0~4000万】的数据是平均分配到3个DB中的,那就不能够实现按照服务器能力适当分配了。
按照Table总数10就能够达到,看如何达到:
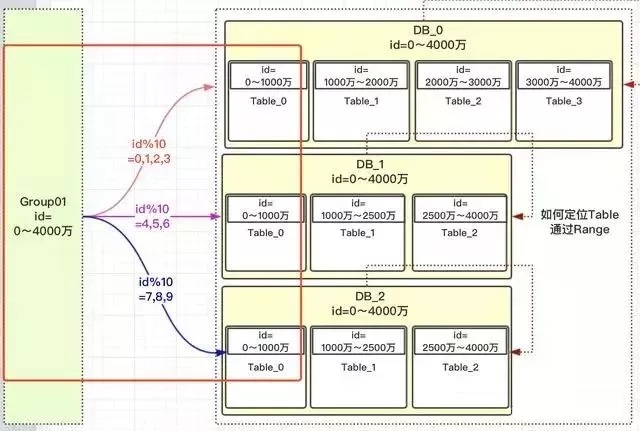
上图中我们对10进行取模,如果值为【0,1,2,3】就路由到 DB_0,【4,5,6】路由到 DB_1,【7,8,9】路由到 DB_2。
现在小伙伴们有没有理解,这样的设计就可以把多一点的数据放到DB_0中,其他2个DB数据量就可以少一点。DB_0承担了4/10的数据量,DB_1承担了3/10的数据量,DB_2也承担了3/10的数据量。整个Group01承担了【0,4000万】的数据量。
注意:千万不要被DB_1或DB_2中table的范围也是0~4000万疑惑了,这个是范围区间,也就是id在哪些范围内,落地到哪个表而已。
注意:10张分表的数据并非一样多
- DB_0 共 1600W,4张表实际数量:1600w(1/4)=400w、1600w(1/4)=400w、1600w(1/4)=400w、1600w(1/4)=400w
- DB_1 共 1200W,3张表实际数量:1200w(2/8)=300w、1200w(3/8)=450w、1200w(3/8)=*450w
- DB_2 共 1200W,3张表实际数量:1200w(2/8)=300w、1200w(3/8)=450w、1200w(3/8)=*450w
以 DB_0 的4张表为例:
- DB_0..Table_0 范围:[0,1,2,3] , [10,11,12,13] ... [999w+9990,999w+9991,999w+9992,999w+9993]
- DB_0..Table_1 范围:[1000w+0,1000w+1,1000w+2,1000w+3] ... [1999w+9990,1999w+9991,1999w+9992,1999w+9993]
- DB_0..Table_2 范围:[2000w+0,2000w+1,2000w+2,2000w+3] ... [2999w+9990,2999w+9991,2999w+9992,2999w+9993]
- DB_0..Table_3 范围:[3000w+0,3000w+1,3000w+2,3000w+3] ... [3999w+9990,3999w+9991,3999w+9992,3999w+9993]
上面一大段的介绍,就解决了热点的问题,以及可以按照服务器指标,设计数据量的分配。
六、如何扩容
其实上面设计思路理解了,扩容就已经出来了,那就是扩容的时候再设计一个group02组,定义好此group的数据范围就ok了。
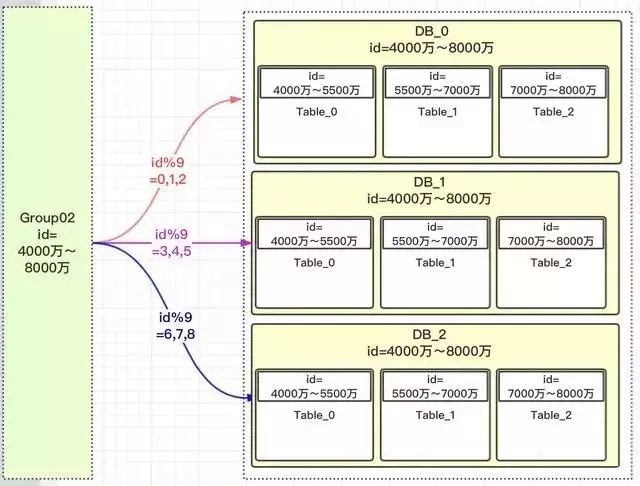
灵活起见,扩容方案甚至修改了模数,3个db配置了9张分表。
因为完全是新增的group组,所以就没有什么数据迁移概念,而且这个group02组同样防止了热点,也就是:
- 【4000万~5500万】的数据,都均匀分配到三个DB的table_0表中;
- 【5500万~7000万】的数据,都均匀分配到三个DB的table_1表中;
- 【7000万~8000万】的数据,都均匀分配到三个DB的table_2表中;
七、系统设计
思路确定了,设计是比较简单的,就3张表,把group、db、table之间建立好关联关系就行了。
group和id的关系,采用range
| group_id | group_name | start_id | end_id |
|---|---|---|---|
| 1 | group01 | 0 | 40000000 |
| 2 | group02 | 40000000 | 80000000 |
group和db的关系,采用hash,即:(id)%10
| db_id | db_name | group_id | hash_value |
|---|---|---|---|
| 1 | g01_db_0 | 1 | 0,1,2,3 |
| 2 | g01_db_1 | 1 | 4,5,6 |
| 3 | g01_db_2 | 1 | 7,8,9 |
| 4 | g02_db_0 | 2 | 0,1,2,3 |
| 5 | g02_db_1 | 2 | 4,5,6 |
| 6 | g02_db_2 | 2 | 7,8,9 |
table和db的关系
| table_id | table_name | db_id | start_id | end_id |
|---|---|---|---|---|
| 1 | table_0 | 1 | 0 | 10000000 |
| 2 | table_1 | 1 | 10000000 | 20000000 |
| 3 | table_2 | 1 | 20000000 | 30000000 |
| 4 | table_3 | 1 | 30000000 | 40000000 |
| 5 | table_0 | 2 | 0 | 10000000 |
| 6 | table_1 | 2 | 10000000 | 25000000 |
| 7 | table_2 | 2 | 25000000 | 40000000 |
| 8 | table_0 | 3 | 0 | 10000000 |
| 9 | table_1 | 3 | 10000000 | 25000000 |
| 10 | table_2 | 3 | 25000000 | 40000000 |
| 11 | table_0 | 4 | 40000000 | 55000000 |
| 12 | table_1 | 4 | 55000000 | 70000000 |
| 13 | table_2 | 4 | 70000000 | 70000000 |
| 14 | table_0 | 5 | 40000000 | 55000000 |
| 15 | table_1 | 5 | 55000000 | 70000000 |
| 16 | table_2 | 5 | 70000000 | 80000000 |
| 17 | table_0 | 6 | 40000000 | 55000000 |
| 18 | table_1 | 6 | 55000000 | 70000000 |
| 19 | table_2 | 6 | 70000000 | 80000000 |
上面的表关联其实是比较简单的,只要原理思路理顺了,就ok了。小伙伴们在开发的时候不要每次都去查询三张关联表,可以保存到缓存中(本地jvm缓存),这样不会影响性能。
一旦需要扩容,小伙伴是不是要增加一下group02关联关系,那应用服务需要重新启动吗?
简单点的话,就凌晨配置,重启应用服务就行了。但如果是大型公司,是不允许的,因为凌晨也有订单的。那怎么办呢?本地jvm缓存怎么更新呢?
其实方案也很多,可以使用zookeeper,也可以使用分布式配置,这里是比较推荐使用分布式配置中心的,可以将这些数据配置到分布式配置中心去。
八、10亿大表实践
场景
某订单系统,预计2年产生10亿条记录。
设计
- 基于性能考虑,按照每张表1000W行设计,预计100张分表;
- 按照100张分表考虑,建议1个group共10个库、每个库10张分表;
- 2年后再考虑扩容一个group;
方案
group和id的关系,采用range
| group_id | group_name | start_id | end_id |
|---|---|---|---|
| 1 | group01 | 0 | 10亿 |
group和db的关系,采用hash,即:id%100
| db_id | db_name | group_id | hash_value |
|---|---|---|---|
| 1 | g01_db00 | 1 | [0~9] |
| 2 | g01_db01 | 1 | [10~19] |
| 3 | g01_db02 | 1 | [20~29] |
| 4 | g01_db03 | 1 | [30~39] |
| 5 | g01_db04 | 1 | [40~49] |
| 6 | g01_db05 | 1 | [50~59] |
| 7 | g01_db06 | 1 | [60~69] |
| 8 | g01_db07 | 1 | [70~79] |
| 9 | g01_db08 | 1 | [80~89] |
| 10 | g01_db09 | 1 | [90~99] |
table和db的关系,以 g01_db00 这一个db为例:
| table_id | table_name | db_id | start_id | end_id | hash_value | 取值范例 |
|---|---|---|---|---|---|---|
| 1 | table00 | 1 | 0 | 10000000 | [0~9] | [0~9], [100~109] ... [9999900~9999909] |
| 2 | table01 | 1 | 10000000 | 20000000 | [0~9] | [1000w~1000w+9] ... [19999900~19999909] |
| 3 | table02 | 1 | 20000000 | 30000000 | [0~9] | [2000w~2000w+9] ... [29999900~29999909] |
| 4 | table03 | 1 | 30000000 | 40000000 | [0~9] | [3000w~3000w+9] ... [39999900~39999909] |
| 5 | table04 | 1 | 40000000 | 50000000 | [0~9] | [4000w~4000w+9] ... [49999900~49999909] |
| 6 | table05 | 1 | 50000000 | 60000000 | [0~9] | [5000w~5000w+9] ... [59999900~59999909] |
| 7 | table06 | 1 | 60000000 | 70000000 | [0~9] | [6000w~6000w+9] ... [69999900~69999909] |
| 8 | table07 | 1 | 70000000 | 80000000 | [0~9] | [7000w~7000w+9] ... [79999900~79999909] |
| 9 | table08 | 1 | 80000000 | 90000000 | [0~9] | [8000w~8000w+9] ... [89999900~89999909] |
| 10 | table09 | 1 | 90000000 | 100000000 | [0~9] | [9000w~9000w+9] ... [99999900~99999909] |
举例:以80000129为例:
- 1.根据range范围定位哪个group,这里 0 < id < 10亿,得出 group_id=1,即 group01
- 2.根据hash方案定位哪个db,这里 id % 100 = 29,得出 db_id=3,即:g01_db02
- 3.根据range方案定位哪个table,这里 id 在【8000w ~ 9000w】,得出 table_id=9,即:table08
综上得出,id=80000129 存放在 g01_db02..table08
九、分库分表引起的问题
分库分表按照某种规则将数据的集合拆分成多个子集合,数据的完整性被打破,因此在某种场景下会产生多种问题。
扩容与迁移
以上方案完美解决了扩容与迁移的问题,暂不讨论。
分库分表维度导致的查询问题
在分库分表以后,如果查询的标准是分片的主键,则可以通过分片规则再次路由并查询;但是对于其他主键的查询、范围查询、关联查询、查询结果排序等,并不是按照分库分表维度来查询的。
例如,用户购买了商品,需要将交易记录保存下来,那么如果按照买家的纬度分表,则每个买家的交易记录都被保存在同一表中,我们可以很快、很方便地查到某个买家的购买情况,但是某个商品被购买的交易数据很有可能分布在多张表中,查找起来比较麻烦。
反之,按照商品维度分表,则可以很方便地查找到该商品的购买情况,但若要查找到买家的交易记录,则会比较麻烦。
所以常见的解决方式如下:
- 在多个分片表查询后合并数据集,这种方式的效率很低。
- 记录两份数据,一份按照买家纬度分表,一份按照商品维度分表。数据分别存储,并从不同的系统提供接口。
- 通过搜索引擎解决,但如果实时性要求很高,就需要实现实时搜索。
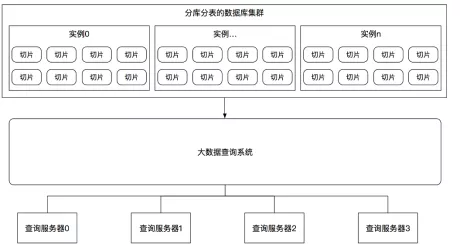
查询的问题最好在单独的系统中使用其他技术来解决,而不是在交易系统中实现各类查询功能;同时,关联的表有可能不在同一数据库中,所以基本不可能进行联合查询,需要通过大数据技术统一聚合和处理关系型数据库的数据,然后对外提供查询操作。
通过大数据方式来提供聚合查询的方式如下图示。
跨库事务难以实现
要避免在一个事务中同时修改数据库db0和数据库db1中的表,因为操作起来很复杂,对效率也会有一定的影响。
同组数据跨库问题
要尽量把同一组数据放到同一台数据库服务器上,不但在某些场景下可以利用本地事务的强一致性,还可以使这组数据自治。
以电商为例,某应用有两个数据库db0和db1,分库分表后,按照id维度,将卖家A的交易信息存放到db0中。当数据库db1挂掉时,卖家A的交易信息不受影响,依然可以正常使用。也就是说,要避免数据库中的数据依赖另一数据库中的数据。
以上的方案介绍结束,希望对大家有所帮助。