mysql主从常用操作
[TOC]
常用的操作
- [x] [主库] 查看以本机为主库的从库信息
show slave hosts;
- [x] [从库] 查看主从状态信息
show slave status;
- [从库] 查看复制的详细错误
select * from performance_schema.replication_applier_status_by_worker;
- MySQL 8.x 的主从账号密码是明文保存在这张表里的
select * from mysql.slave_master_info;
- [x] 禁用skip-slave-start之后,slave进程会随着mysql启动而启动
skip-slave-start=0
- 多实例从库管理
mysqld_multi report
mysqladmin -uroot -p -S /tmp/mysql.sock6148 shutdown
mysqld_multi start xxx
跳过错误
- 跳过1条错误记录:不建议超过3次
stop slave;set global sql_slave_skip_counter=1;start slave;
- 跳过某类错误:修改my.cnf添加 slave_skip_errors 参数,并重启mysql服务生效。
[mysqld]
slave_skip_errors=1032,1062
mysql> show variables like '%slave_skip%';
筛选库表同步
- [不建议] 只同步某个库
STOP SLAVE;
CHANGE REPLICATION FILTER REPLICATE_DO_DB = (db1, db2);
START SLAVE;
- [不建议] 跳过某个表或库的同步
STOP SLAVE;
CHANGE REPLICATION FILTER Replicate_Ignore_DB=('db_x1');
CHANGE REPLICATION FILTER replicate_wild_ignore_table=('table_x1','table_x2');
START SLAVE;
- [不建议] 取消跳过某个表或库的同步
STOP SLAVE;
CHANGE REPLICATION FILTER Replicate_Ignore_DB=('');
CHANGE REPLICATION FILTER replicate_wild_ignore_table=('');
START SLAVE;
- 切记:使用replicate_do_db和replicate_ignore_db时有一个隐患,跨库更新时会出错。原因是设置replicate_do_db或replicate_ignore_db后,MySQL执行sql前检查的是当前默认数据库,所以跨库更新语句在Slave上会被忽略。
比如在Master服务器上设置 replicate_do_db=test(my.conf中设置),那么Slave服务器上第二句将不会被执行
use mysql;
update test.table1 set ...
比如Master设置 replicate_ignore_db=mysql,那么Slave上第二句会被忽略执行
use mysql;
update test.table1 set ...
- [x] [推荐] 在Slave上使用 replicate_wild_do_table 和 replicate_wild_ignore_table 以解决跨库更新的问题,如下:
replicate_wild_do_table=kidstools.%
replicate_wild_ignore_table=mysql.%
删除复制
stop slave;
reset slave all;
show slave status 参数详解
mysql> SHOW SLAVE STATUS \G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.0.28
Master_User: dba_repl
Master_Port: 3306
Connect_Retry: 60 #.连接中断后重新尝试连接的时间间隔,默认值是60秒
Master_Log_File: mysql-bin.000031 #.当前I/O线程正在读取的主服务器二进制日志文件的名称
Read_Master_Log_Pos: 821699240 #.当前I/O线程正在读取的二进制日志的位置
Relay_Log_File: repl-bin.018293 #.SQL线程正在读取和执行的中继日志文件的名称
Relay_Log_Pos: 273 #.在当前的中继日志中,SQL线程已读取和执行的位置
Relay_Master_Log_File: mysql-bin.000031 #.当前slave SQL线程从relay log中读取的正在执行的sql语句,对应主库的sql语句记录在主库的哪个binlog日志中
Slave_IO_Running: Yes #.I/O线程是否被启动并成功地连接到主服务器上
Slave_SQL_Running: Yes #.SQL线程是否被启动
Replicate_Do_DB: #.不建议用,跨库更新时会出错
Replicate_Ignore_DB: #.不建议用,跨库更新时会出错
Replicate_Do_Table: #.不建议用,跨库更新时会出错
Replicate_Ignore_Table: #.不建议用,跨库更新时会出错
Replicate_Wild_Do_Table: db1.%,db2.% #.推荐,只同步哪些表
Replicate_Wild_Ignore_Table: mysql.% #.推荐,不要同步哪些表
Last_Errno: 0 #.slave的SQL线程读取日志参数的错误数量和错误消息
Last_Error:
Skip_Counter: 0 #.SQL_SLAVE_SKIP_COUNTER的值,用于设置跳过sql执行步数
Exec_Master_Log_Pos: 821699240 #.slave的SQL线程当前执行的事件,对应在 Relay_Master_Log_File 中的position
Relay_Log_Space: 592 #.所有原有的中继日志结合起来的总大小
Seconds_Behind_Master: 0 #.从库SQL线程和I/O线程之间的时间差,单位为秒。如果为0,则表示主从同步无延时,反之同步存在延时
Master_Server_Id: 206
Master_UUID: 821-a141-118-84d-012
Master_Info_File: mysql.slave_master_info #.配置复制的账号信息都保存在这张表或者一个文件
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Auto_Position: 0
优化主从的设置
主库从库的通用设置
- [x] 主库通用设置
set global sync_binlog=1; #.每x次事务提交,设为1最安全但性能损耗也最大
set global sync_relay_log=1; #.
show variables like 'sync_%og'; #.
- [x] 从库通用设置
set global read_only=on; #.设置只读模式
set global relay_log_purge=0; #.若采用MHA架构则建议设为0以禁止自动清除relaylog
set global sync_binlog=5000000; #.每x次事务提交,设大一点则效率更好
set global sync_relay_log=5000000; #.默认为10000,即每10000次sync_relay_log事件会刷新到磁盘
set global innodb_flush_log_at_trx_commit=0; #.
show variables like 'sync_%og';
设置从库为只读状态
set global read_only=1;
以上设置从库为只读状态,需要注意如下:
- [x] 不影响slave同步复制
- [x] 重启失效,所以从库重启后需重新设置
- [x] 不会限制具有super权限的用户的dml操作
设置只读状态之升级版:
- [x] 若要限制包括具有super权限的用户也不能进行dml操作,请参考下面。但若发生主从切换则需要 unlock tables; set global read_only=0;
flush tables with read lock;
set global read_only=1;
加快延迟消化
- [x] [从库]当从库延迟大的时候,加快延迟消化的设置(升为主库再改回 主库通用设置).
show variables like '%sync%log%';
set global sync_binlog=5000000;
set global sync_relay_log=5000000;
set global innodb_flush_log_at_trx_commit=0;
- [x] [从库]开启基于库的多线程复制的5个my.cnf配置(默认是0,不开启,最大并发数为1024个线程).
slave_parallel_workers=8
slave_parallel_type=LOGICAL_CLOCK
master_info_repository=TABLE
relay_log_info_repository=TABLE
relay_log_recovery=1
[达达]从库延迟大的优化方案
- 优化Mysql参数,比如增大innodb_buffer_pool_size,让更多操作在Mysql内存中完成,减少磁盘操作。
- 使用高性能CPU主机
- 数据库使用物理主机,避免使用虚拟云主机,提升IO性能
- 使用SSD磁盘,提升IO性能。SSD的随机IO性能约是SATA硬盘的10倍。
- 业务代码优化,将实时性要求高的某些操作,使用主库做读操作
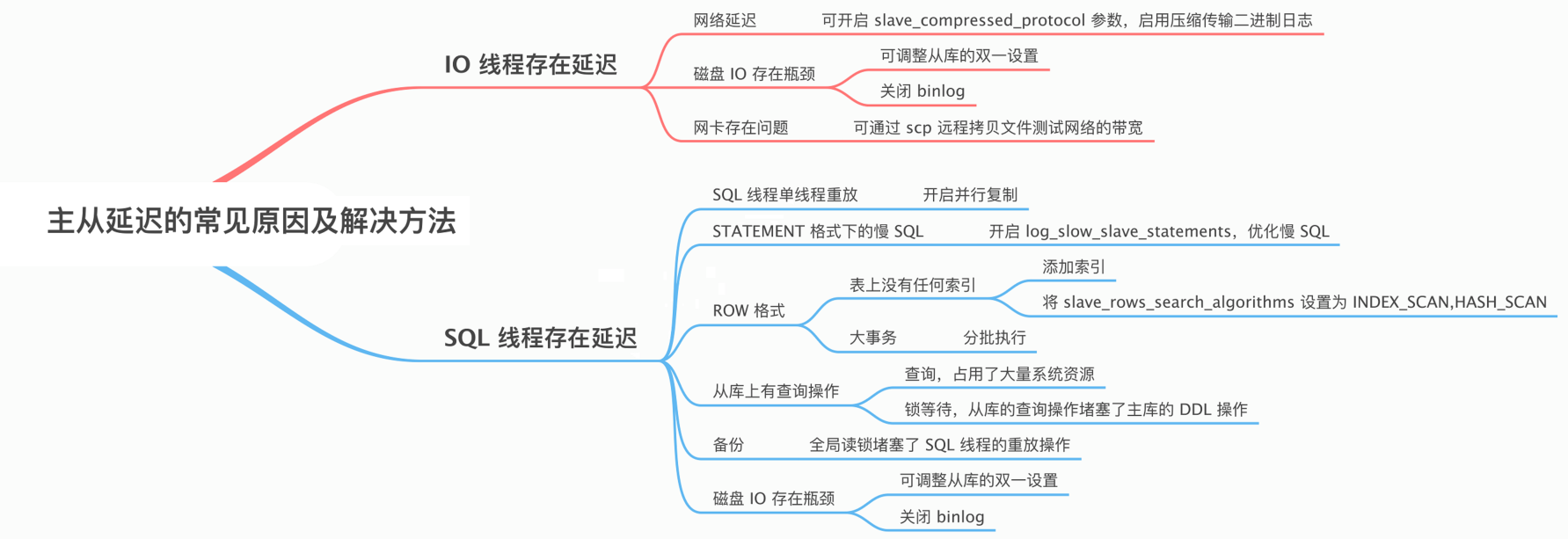
附:主从延迟的常见原因及解决方法如下图所示
关于relay_log清理
- [x] 若仅仅是主从复制,没有mha高可用架构,建议 relay_log_purge=1 允许SQL线程在执行完一个 relay log 后自动将其删除,设置之后已执行的repl-bin.xxx文件将被立刻删除。
show variables like 'relay_log_purge';
set global relay_log_purge=1;
[x] 若采用MHA架构,建议 relay_log_purge=0; 禁止系统自动清除relay log
在MHA高可用架构中切换的步骤中,主要靠对各个实例的relay log文件新旧程度进行比较,选取最新的relay log进行群组内的数据追加,以此尽可能地来保证数据的安全性,减少数据丢失的数量。这就要求relay log不能被系统自动清除,要保留一段时间,防止主库挂掉,进行数据补全。
[x] 但这就会产生一个问题,在业务持续繁忙时,从库可能会积累很多relay log,若不及时清除早晚会酿出祸患。这里建议使用purge_relay_logs工具进行定时清理relay_log,脚本参考如下:
host=127.0.0.1
port=3306
user=dba_admin
password=***
/usr/bin/purge_relay_logs --user=$user --password=$password --port=$port --host=$host
常见问题处理
[常见] 接上主从位置(未启用gtid)
分析:从"show slave status\G"的输出中找到如下信息
Relay_Master_Log_File: mysql-bin.000265 #.slave库已读取的master的binlog
Exec_Master_Log_Pos: 239381407 #.在slave上已经执行的position位置点
解决:停掉slave,以slave已经读取的binlog文件和已经执行的position为起点,重新设置同步,会产生新的中继日志,问题解决。
stop slave;
change master to master_log_file='mysql-bin.000265', master_log_pos=239381407;
start slave;
深度:从"show slave status\G"的输出中找到这个relay日志并分析
Relay_Log_File: mysql03-relay-bin.001992
Relay_Log_Pos: 180325546
mysqlbinlog mysql03-relay-bin.001992 > /data/123.txt
[常见] 接上主从位置(启用gtid的话)
- [ ] 若启用gtid的话,直接 master_auto_position=1; 不用再找点位了。
stop slave;
change master to master_auto_position=1;
start slave;
注:2021.11.17.实测,主库 show binary logs; 看到最早的binlog日志为 mysql-bin.000395,而从库 Master_Log_File: mysql-bin.000134,相差太多,接不上了。
Master_Log_File: mysql-bin.000303
Read_Master_Log_Pos: 274867023
Relay_Log_File: repl-bin.000002
Relay_Log_Pos: 414
Relay_Master_Log_File: mysql-bin.000303
Slave_IO_Running: No
Slave_SQL_Running: No
Last_Errno: 1032
Last_Error: Coordinator stopped because there were error(s) in the worker(s). The most recent failure being:
Worker 1 failed executing transaction '522b6a42-d4c0-11eb-835a-00163e11f119:356651666' at master log , end_log_pos 257388414.
See error log and/or performance_schema.replication_applier_status_by_worker table for more details about this failure or others, if any.
Exec_Master_Log_Pos: 257387826
Master_UUID: 522b6a42-d4c0-11eb-835a-00163e11f119
Retrieved_Gtid_Set: 522b6a42-d4c0-11eb-835a-00163e11f119:356651666-356670431
Executed_Gtid_Set: 522b6a42-d4c0-11eb-835a-00163e11f119:1-356651665,53932847-d4c0-11eb-825b-00163e17a171:1-209
Auto_Position: 1
- [ ] 如下方案(设置
@@SESSION.GTID_NEXT为从库Executed_Gtid_Set中gtid+ 1):2023.06.28.实测.问题依旧
stop slave;
set @@SESSION.GTID_NEXT='522b6a42-d4c0-11eb-835a-00163e11f119:356651666';
BEGIN; COMMIT;
SET SESSION GTID_NEXT = AUTOMATIC;
start slave;
- [ ] 如下未尝试,GTIT模式跳过某个错误:
从库:执行如下,记录一下 Executed_Gtid_Set,比如 7f8d9eb8-a7fe-11e2-84fd-0015177c251e:1-260,然后重置。
show slave status\G; #.记住 Executed_Gtid_Set
reset master;
stop slave;
reset slave;
从库:若要直接跳过这1条错误,可在其ID上加1即可,比如 7f8d9eb8-a7fe-11e2-84fd-0015177c251e:1-261
set global gtid_purged='7f8d9eb8-a7fe-11e2-84fd-0015177c251e:1-261′;
CHANGE MASTER TO MASTER_HOST='192.168.1.136', MASTER_PORT=3306, MASTER_USER='dba_repl',MASTER_PASSWORD='MA6RuouuZZn4x_Hd', master_auto_position=1;
start slave;
show slave status\G;
[常见] 1062错误
场景:1062错误报错如下:
Last_Errno: 1062
Last_Error: Coordinator stopped because there were error(s) in the worker(s). The most recent failure being: Worker 0 failed executing transaction '' at master log mysql-bin-3306.000002, end_log_pos 1865.
解决:执行如下语句,查看具体的报错原因
select * from performance_schema.replication_applier_status_by_worker;
[常见] 1236错误
场景1:1236错误报错如下:
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Client requested master to start replication from position > file size'
mysql.err日志报错如下:
[ERROR] Error reading packet from server for channel '': Client requested master to start replication from position > file size (server_errno=1236)
[ERROR] Slave I/O for channel '': Got fatal error 1236 from master when reading data from binary log: 'Client requested master to start replication from position > file size', Error_code: 1236
[Note] Slave I/O thread exiting for channel '', read up to log 'mysql-bin.000005', position 968483446
[Note] Slave SQL thread for channel '' initialized, starting replication in log 'mysql-bin.000005' at position 968483446, relay log './relay-bin.000008' position: 968445827
场景2:已存在数据的GTID从库掉电重启,或在主库上手动清除binlog文件,则会报1236错误如下:
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'
解决方案:
- 主库:获取 gtid_purged(
不是gtid_executed哦)
show global variables like '%gtid%';
- 从库:执行如下:
stop slave;reset slave;reset master;
# set global gtid_purged='5ff4d38d-89cd-11ea-8555-000c292b3340:1-15';
CHANGE MASTER TO MASTER_HOST='192.168.64.128',MASTER_PORT=3406,MASTER_USER='dba_repl',MASTER_PASSWORD='MA6RuouuZZn4x_Hd',Master_Auto_Position=1;
start slave;show slave status\G;
- 利用 mk-table-checksum 确认主从数据是否一致
[常见] 2061错误
场景:启用gtid的 MySQL 8 遇到2061错误报错如下:
Last_IO_Errno: 2061
Last_IO_Error: error connecting to master 'dba_repl@x.x.x.x:3406' - retry-time: 60 retries: 1 message: Authentication plugin 'caching_sha2_password' reported error: Authentication requires secure connection.
解决方案:
从库:重置主从,并指定get_master_public_key=1
stop slave;
reset slave;
change master to master_host='x.x.x.x',master_port=3406,master_user='dba_repl',master_password='***',master_auto_position=1,get_master_public_key=1;
start slave;
[优化] 从库延迟大而导致repl-bin.xxx目录达到1.7T
从库:确认
show slave status\G;
Master_Log_File : mysql-bin.001324
Read_Master_Log_Pos : 412158859
Relay_Log_File : repl-bin.003965
Relay_Log_Pos : 18497482
Relay_Master_Log_File : mysql-bin.001324 #.slave库已读取的master的binlog
Seconds_Behind_Master : 36496 #.看这里
主库:确认
show binary logs;
+------------------+------------+
| mysql-bin.001393 | 1073745637 |
| mysql-bin.001394 | 577713181 | #.看这里
+------------------+------------+
比对发现:mysql-bin.xxx还有70个未同步(主库.001394,从库.001324)
从库:为了腾出空间,修改binlog最长保存期限(8天改为1天),再flush logs生效。
show variables like 'expire_logs_days';
set global expire_logs_days=1;
flush logs;
从库:设置 relay_log_purge=1 允许SQL线程在执行完一个 relay log 后自动将其删除,设置之后已执行的repl-bin.xxx文件将被立刻删除。
show variables like 'relay_log_purge';
set global relay_log_purge=1;
从库:调整参数加快同步
show variables like '%sync%log%';
set global sync_binlog=5000000;
set global sync_relay_log=5000000;
set global innodb_flush_log_at_trx_commit=0;
从库:待延迟追平,再改回配置(改大expire_logs_days不需要flush logs)。
set global expire_logs_days=8;
set global relay_log_purge=0;
[BUG] 重启后主从启动报错
Last_Errno: 1872
Last_Error: Slave failed to initialize relay log info structure from the repository
修复方案:bug参考:Slave failed to initialize relay log info after OS crash when use MTS and GTID
reset slave;
start slave IO_THREAD;
stop slave IO_THREAD;
reset slave;
start slave;