sqlserver为什么会走错执行计划
SQL Server在执行计划中为什么没有使用你认为应该使用的索引?下面针对这个问题做详细的解答。
[TOC]
知识点:为什么数据库会走错执行计划
SQL Server在执行计划中为什么没有使用你认为应该使用的索引?
- 原因1:该语句返回的结果超过了表的20%数据,使得SQL Server 认为scan比seek更有效。
- 原因2:可能是表字段的statistics过期了,不能准确反映数据的分布情况。
可以使用命令UPDATE STATISTICS tablename WITH FULLSCAN来更新它。只有同步的准确的statistics才能保证SQL Server 产生正确的执行计划。过时的老的statistics常会导致SQL Server生成不够优化的甚至愚蠢的执行计划。所以如果你的表频繁更新,而你又觉得和之相关的SQL语句运行缓慢,不妨试试UPDATE STATISTIC with FULLSCAN 语句。你甚至可以使用Index hint比较不同索引的性能差异。
select id from suppliers with(index=idx_name) where name='海底捞'
如果强制使用索引后logical reads大大减少,那么就需要进一步研究为什么SQL Server没有用到正确的索引。
场景1:统计信息不准造成的僵死
场景:一个客户的OLTP系统里,有一句非常重要的查询语句,直接关系到系统的整体性能。某一天查询突然变得非常慢。
处理:在确定了性能问题是由这条查询语句导致后,更新了该表的统计信息,之后性能恢复正常。
--.更新表的所有/指定索引的统计信息
USE BTS
UPDATE STATISTICS ST_MKT_MARKET
UPDATE STATISTICS ST_MKT_MARKET(st_mkt_market_idx1);
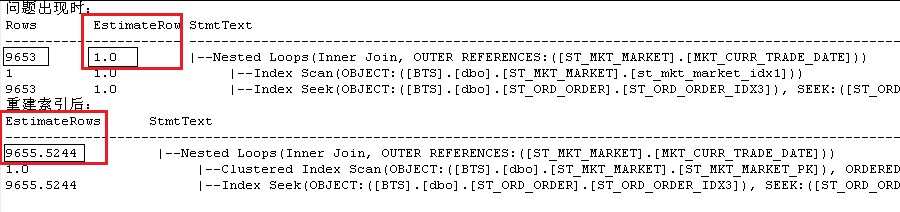
分析:问题出现时,SQL Server预测返回行数(EstimateRow)是1行,而实际返回(Rows)了9653行。更新统计信息后,SQL Server变得能够精确预测返回9655行,和实际的返回值非常接近。由于返回行数预测不准确,SQL Server在选择执行计划的时候犯了一系列错误,导致选择的执行计划很不合理,最后运行时间慢了非常多。
场景2:利用索引提示(index hint)强制索引
场景:2019.08.31.巡检看到如下慢查询,耗时59秒:
USE xxx_pay_trade_basis
exec sp_executesql N'SELECT TOP 25 * FROM [dbo].[UserCmbAccount] WITH (NOLOCK) WHERE [Status] = @P0 AND [IsClosed] = @P1 AND [IsActive] = @P2 ORDER BY [InsertTime] DESC'
,N'@P0 int,@P1 bit,@P2 bit',@P0=2,@P1=0,@P2=1
分析此条语句的资源消耗如下
表'UserCmbAccount'。扫描计数1,逻辑读取144619947 次,物理读取0 次,预读0 次,lob 逻辑读取0 次,lob 物理读取0 次,lob 预读0 次。
CPU 时间= 58812 毫秒,占用时间= 59379 毫秒。
验证无效
- 已存在如下索引 idx_InsertTime,且该索引碎片仅1.23%:
- 更新统计信息仍无效:
update statistics dbo.UserCmbAccount idx_InsertTime - 数据库引擎默认仍使用老索引:idx_UserCmbAccount_InsertTime
验证有效
- 由于此表数据太多(35592126 笔),且相关字段上没有索引,所以我创建如下索引:
CREATE NONCLUSTERED INDEX idx_Status_IsClosed_IsActive@InsertTime ON UserCmbAccount(Status,IsClosed,IsActive) INCLUDE(InsertTime) WITH(FILLFACTOR=90,ONLINE=ON)
- 强制索引 idx_Status_IsClosed_IsActive@InsertTime 后的资源消耗如下:
表 'UserCmbAccount'。扫描计数 4,逻辑读取67 次,物理读取 0 次,预读 9 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
CPU 时间 = 0 毫秒,占用时间 = 7毫秒。
解决办法:推荐第4 > 第3 > 第2 > 第1
- 1.将 TOP 25 改为 TOP 1000 则走对索引(测试发现,非通用建议),可能会返回更多的结果集,请开发定夺;
- 2.使用 index= 查询提示强制使用某索引 WITH (NOLOCK,index=idx_Status_IsClosed_IsActive@InsertTime),为了避免后面踩坑(假如删了该索引则代码会报错),不建议使用;
- 3.使用 forceseek 查询提示强制使用索引查找操作,WITH (NOLOCK,forceseek),从而避免因走错低效的索引扫描而导致的性能问题;
- 4.利用主键来查找,逻辑如下:
SELECT * FROM [dbo].[UserCmbAccount] [UserCmbAccount] WITH (NOLOCK)
WHERE UserID IN(
SELECT TOP 25 UserID FROM [dbo].[UserCmbAccount] WITH (NOLOCK)
WHERE [Status] = 2 AND [IsClosed] = 0 AND [IsActive] = 1
ORDER BY [InsertTime] DESC
)ORDER BY [InsertTime] DESC
场景3:主键碎片过高导致引擎走错执行计划
场景:2020.12.08.开发同事反馈test环境某报表耗时2分钟,sql窗口执行则1秒返回,脚本如下:
exec sp_executesql N'select top 15 * from (
SELECT rai.wjId, wj.wjName, wo.outlineName, sbk.subjectStem, rad.zdContent, rai.remark, rai.feedbackTime, rai.dxMid
, CASE WHEN rai.[status]=1 THEN ''已提交'' WHEN rai.[status]=0 THEN ''已读'' ELSE '''' END feedbackStatusName
FROM (SELECT Id, dcId, pwd,org_code, wjId,remark,created_at feedbackTime, receiverId dxMid, [status] FROM dbo.receiver_answerInfo(NOLOCK) WHERE is_del=0 AND dcId=@dcId AND org_code=@org_code AND created_at BETWEEN @kssj AND @jssj) rai
INNER JOIN dbo.receiver_answerDetail(NOLOCK) rad ON rad.zdId=rai.Id AND rad.is_del=0
INNER JOIN dbo.dc_implement(NOLOCK) di ON di.pwd=rai.pwd
INNER JOIN dbo.wj_Info(NOLOCK) wj ON wj.Id=rai.wjId
INNER JOIN dbo.wj_outline(NOLOCK) wo ON wo.wjId=wj.Id
INNER JOIN dbo.subjects_bank(NOLOCK) sbk ON sbk.Id=rad.subjectId
) queryData order by feedbackTime',N'@dcId varchar(50),@org_code varchar(50),@kssj datetime,@jssj datetime',@dcId='306c7916-fda1-4e86-bcc7-9dc6ee787996',@org_code='jr-gxh',@kssj='2020-10-01 00:00:00',@jssj='2020-12-08 10:22:45'
- 方法1:找到最大表 dc_implement 表pwd字段varchar(200)无索引,添加索引并调整代码并无效果;
- 方法2:找到最大表 dc_implement 主键碎片高达99%,重建pk后1秒返回;
场景4:调整sql逻辑
2021.05.24.开发同事反馈uat环境某sql程序报错超时,sql窗口执行则2秒返回,脚本如下:
SELECT COUNT(*)
FROM [leads] AS [l]
INNER JOIN (
SELECT [l0].[id], [l0].[area_code], [l0].[created_at], [l0].[creator_id], [l0].[deadsea_time], [l0].[deadsea_user], [l0].[deleted_at], [l0].[gain_time], [l0].[gain_user], [l0].[giveup_time], [l0].[giveup_user], [l0].[if_trace], [l0].[IsImportant], [l0].[last_owner], [l0].[last_trace_content], [l0].[last_trace_status], [l0].[last_trace_time], [l0].[last_trace_user], [l0].[lately_trace_time], [l0].[leadsid], [l0].[move_time], [l0].[next_trace_time], [l0].[next_trace_user], [l0].[RecycleDays], [l0].[trace_num], [l0].[trace_reason], [l0].[update_lately_trace_time], [l0].[updated_at], [l0].[updater_id]
FROM [leads_ext] AS [l0]
WHERE [l0].[area_code] = '2'
) AS [t] ON [l].[id] = [t].[leadsid]
WHERE [l].[dept] IN (2, 20, 25, 34, 41, 42, 43, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106) AND [l].[status] IN (CAST(0 AS tinyint), CAST(1 AS tinyint))
- 方法1:对涉及的2张表更新全部信息、重建全部索引,程序仍超时(sql窗口执行一直很快);
注:leads_ext表满足area_code='2'数据占比96%,强制走area_code索引反而更慢(7秒)
select area_code,count(1) as cnt from leads_ext with(nolock) group by area_code order by cnt desc
--数据分布
2 7430546
3 348784
1 2118
4 335
- 方法2:调整sql逻辑将 子查询+inner join 改成 inner join,将area_code和leadsid放在语句同一级条件里,确保命中索引,程序终于快了;
SELECT COUNT([l].id)
FROM [leads] AS [l] WITH(NOLOCK)
INNER JOIN [leads_ext] as [l0] WITH(NOLOCK) ON [l0].[area_code] = '2' AND [l].[id] = [l0].[leadsid]
WHERE [l].[status] IN (CAST(0 AS tinyint), CAST(1 AS tinyint))
AND [l].[dept] IN (2, 20, 25, 34, 41, 42, 43, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106)